 公式資料
公式資料
「デジタルオペレーションの現状」独自調査レポート
エンジニアの燃え尽きを防ぐ秘訣とは?
一段と信頼性の高いシステムを顧客が求めるようになり、勤務時間外や夜間の対応など、技術チームへの要求も増しています。本レポートでは、19,000 社以上、100 万人を超えるユーザーで構成されるPagerDutyプラットフォームから収集したデータを基にしたシステム運用の”今”を解説!→ PagerDutyの資料をみる(無料)


2020年以降、コロナ禍において人々の働き方や暮らし方、人との付き合い方や学び方は大きく変化しました。その状況下でも顧客が“ニューノーマル”にうまく適応できるように、私たちPagerDutyの技術チームはオンラインでできることを可能な限りすべてを実行してきました。しかし一方で、そうした取り組みに伴って、システム障害やインシデントが増加し、技術チームは予期しない業務の対応に追われることとなりました。
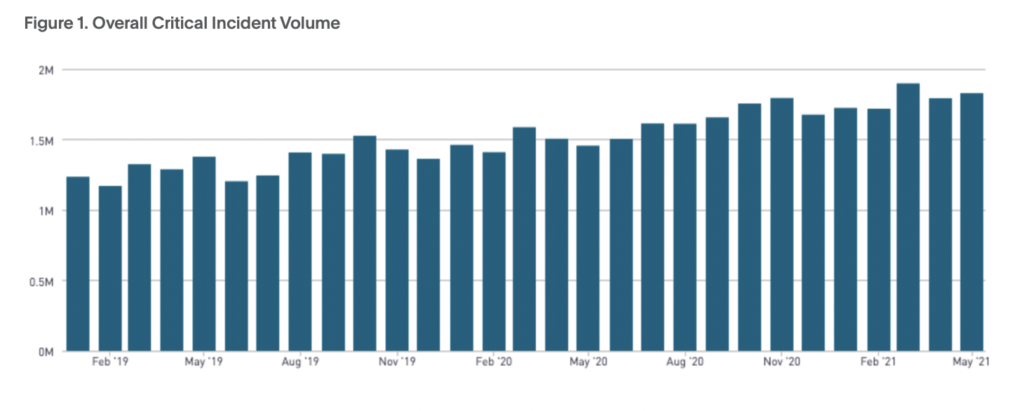
2021年にPagerDutyが独自のプラットフォームデータに基づいて初めて作成したレポート「デジタルオペレーションの現状レポート」では、「技術チームの2020年の業務量が2019年と比較してどれほど変化したのか」を示しています。労働時間は平均で1日につき2時間増え、MTTR(平均修復時間)とMTTA(平均確認時間)などの一般的な指標・基準で見た重大なインシデント数は19%増加しました。インシデント対応に起因するプレッシャーは技術チームメンバーの疲労や激しい消耗などにつながっています。
DXが進む昨今、さまざまなデジタルシステムからのアラートやインシデントは増え続けています。顧客に安定したサービスを届けるために、リアルタイムでの対応が必要な作業が急激に増加するなかで迅速に対応するためにはどうすればよいのでしょうか。今回の記事では、そうした要求が高まる状況のなかで私たちPagerDuty自身が得た学びを基に「インシデント対応を改善し、より迅速な対応をとるためにチームが確認すべき10のチェックポイント」をご紹介します。
目次
現代のビジネスは、すばらしい顧客体験を提供するにあたって膨大かつ複雑なデジタルサービスに依存しています。デジタルサービスは常時稼働することを求められますが、システムが複雑であればあるほどシステム障害を避けることは難しくなります。システム障害ような事態が生じると組織はリアルタイムの作業が必要なインシデント対応に直面します。
多くの企業では、インシデントが発生すると手作業でインシデントに関する通知を発信し、非効率的な部門横断型の連携を図ります。そのため組織間の情報共有や連携に時間がかかり、迅速かつ効果的なインシデント対応がとれていません。インシデントに対応する技術チームは、常に目の前の問題やインシデントの解決に追われる状態になり、デジタルサービスの質を高める作業が後回しになりがちです。そうなると、顧客の期待に応えることが難しくなり「組織の収益」と「顧客との関係」に悪影響が及ぶ可能性が生じることがあります。
本記事冒頭でも述べたとおり、PagerDutyの利用データによれば、2020年の重大なインシデントの数は前年比で19%増加しました。ここでいう重大なインシデントとは「5分以内に自動解決されず、4時間以内に確認され、24時間以内に解決した、緊急対応が必要なインシデント」を指しています。一方で、重大なインシデント数が増加傾向にあるにもかかわらず、PagerDutyを5年以上利用している方のMTTA(平均確認時間)とMTTR(平均修復時間)は減少しています。また、PagerDutyの利用時間が長いほど、MTTAとMTTRが短くなる傾向にあることがわかりました。これは、デジタルオペレーション強化に注力することにより、インシデント対応における社内連携が強化されたことを示しています。そして、MTTAの減少は、ステークホルダーへの簡潔かつ正確な状況説明の大切さがより認知されたことを示しているといえます。というのも、MTTAの減少は「確認率(オンコール技術者が確認したアラートの数)の上昇」を意味するからです。
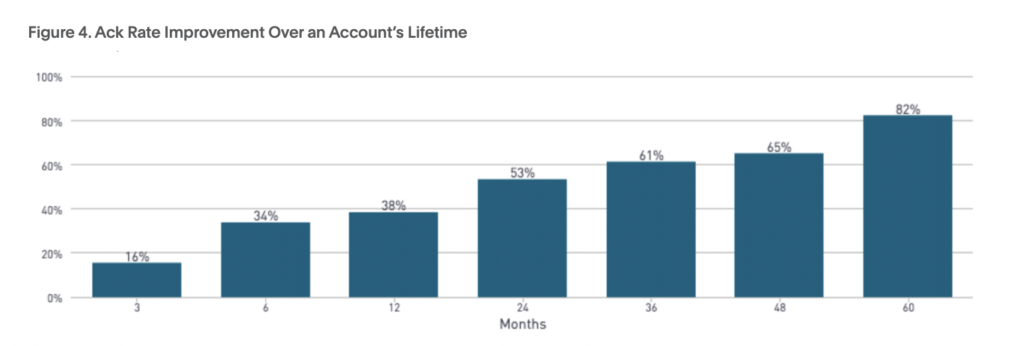
MTTAなどの測定指標・基準は、インシデント対応プロセスやデジタルオペレーションの成熟度そのものを示すものではありません。しかし、そうした数値から得られる総合的なパフォーマンスから得られるインサイトを使えば「チームの強み」と「改善点」を洗い出すことが可能になります。
一方で、MTTAとMTTRが短くなっても増える傾向にあるのが「インシデント解決に必要な総時間」です。理想的なのは、インシデントの件数が増えたとしても、インシデント解決の効率化を進めることで全体の対応時間を増やさず保つことです。その際に大切なのが「身を粉にするインシデント解決方法」ではなく「いかに効率的なインシデント対応を実現するか」という点です。そうした効率的なインシデント対応の実現に向けて、インシデント対応のライフサイクルの要素一つひとつをどのように最適化すべきかを見ていきましょう。
インシデント対応については以下の記事でも詳しく解説しています。ぜひ併せてご覧ください。
> 「インシデント対応」とは?〜効率的な体制構築のポイントを解説〜
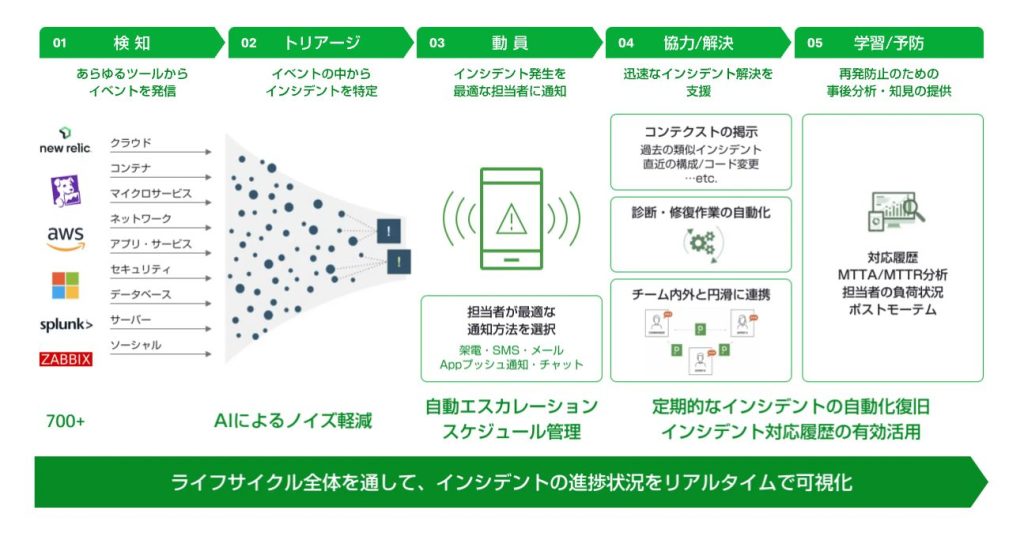
「インシデント対応のライフサイクル」とは、企業のシステム障害発生後の「インシデントの検知、顧客への影響の防止、状況の診断、対応チームの配置(動員)、問題の解決、事後学習/予防」という一連のプロセスのことです。このサイクルにおけるどの段階でも「インシデント解決の効率化」といったオペレーション上の課題が見つかるはずです。ここから、インシデント対応のライフサイクルにおける効率化に向けた10のチェックポイントご紹介します。
Point 1. インシデントの分類スキームは組織内で周知されているか?
Point 2. インシデントの性質に合わせて対応者が最適化されているか?
Point 3. インシデント対応者を呼び出す方法は最適か?
Point 4. 自動化でさらに業務を迅速化できないか?
Point 5. 変更を追跡し、その情報を利用できるようにしているか?
Point 6.「技術面」と「ビジネス面」で他のサービスへの影響度を把握しているか?
Point 7.「時間」を最も重要視した場合に、ベストな協業体制になっているか?
Point 8. 各ステークホルダーへの情報提供方法が管理されているか?
Point 9. 効果的なレトロスペクティブ(振り返り)になっているか?
Point 10. 解決で得た学びを今後のインシデント対応プロセスに活かせているか?
インシデントの検知・検出方法にはいくつかのケースがありますが、なかでも最適な方法の一つといえるのは「モニタリングで異常が検知され注意喚起の通知を受けるケース」です。一方、ワーストシナリオとも言えるのが「顧客から問題の発生を指摘されるケース」です。いずれのケースにせよ、次のチェックポイントを事前に確認しておけば、より迅速なインシデント対応への道がひらけます。
インシデントを分類する際には、チームによって「重大度を基準にすべき」という意見と「優先度を基準にすべき」という意見に社内で分かれるかもしれません。いずれの基準を採用するにせよ重要なのは「そのチームではインシデントがどう分類されているのか」をチームメンバー全員が理解していることです。メンバーが正しくSev1とSev3の違いを理解していれば、インシデントの発生時に現場がまとまります。
仮に重大度・深刻度を基準にインシデントを分類するとします。そして、重大度別に情報を共有して対応するメンバーを役割を基準に決めます。例えば、Sev3ではオンコール技術者が1名で対応し、Sev1ではマネジメントを含むチーム全員が対応するという具合です。こうしたプランがあれば、ミッションクリティカルなインシデントが発生した際に「対応者が決まらない状態」を回避することが可能です。
顧客への影響を最小限に抑えるためには「早急に適切なメンバーを呼び出すこと」そして「業務を可能な限り自動化」が必要です。これがインシデント対応時間短縮に直結する方法ですが、さしあたって以下のチェックポイントで改善できることがあるかどうか確認してみましょう。
Point 2で「重大度別に情報を共有すべきメンバーを決めておくこと」が重要だとご紹介しました。それでは、実際にインシデントが発生した場合、対応者を迅速に配置するためにはどのような方法を選択することが良いでしょうか? 現在のオンコール方法が果たして最適であるか改めてチェックしてみましょう。
インシデント対応者を呼び出す最適な方法の一つが「フルサービスオーナーシップと詳細なオンコールローテーション」を使う方法です。「フルサービスオーナーシップ」とは、ソフトウェアの開発者が運用まで責任を持ってサポートすることを意味します。すべてのサービスを明確に分類し、サービスごとに配置するチームを決めておけば、どのチームがどのインシデントを担当するのかをすぐに把握できます。さらに、詳細な「オンコールローテーション」を用意しておけば、サービスに問題が発生した際のアラートが適切なエンジニアに送られ速やかなインシデント対応を後押しします。
「フルサービスオーナーシップ」は、アジャイルやDevOpsと並び、今日の複雑なクラウド環境において注目される運用モデルです。「フルサービスオーナーシップ」にご興味のある方は、こちらの無料eBook「フルサービスオーナーシップに向けた文化的トランスフォーメーションの推進」をぜひご参考にしてください。
「人間が介在することなくインシデントを自動修復すること」が可能なサービスも世の中にありますが、自動修復で対応できるのは「最も一般的なインシデント」に限られるのが一般的です。PagerDutyを使うと、まず小さな業務を自動化したうえで自動化された業務を繋げて複雑なシーケンスを作成するといったアプローチも可能です。
インシデントを理解する際に重要になるのが「想定される原因は何か」「依存関係のあるサービスで影響を受けたものは何か」といった視点を持つことです。インシデントの発生原因を突き止めるには「何かしらの変更が自分の担当するサービスに影響していないか」「相互に依存関係にあるエコシステム全体への影響はどうなるか」といった点を調査する必要があります。
インシデントの原因としてよく挙げられるのは「コードベースの変更」です。コードベースなどシステム上の変更を管理するツールがあれば、直近のデプロイメントを調べることでインシデント発生原因として想定できるアラートをより早く発見することが可能です。システム上の変更を常に追跡し、インシデント対応を行うすべてのオンコール技術者がその追跡情報を利用できるしておくことが望ましいと言えます。
自分が担当するサービスが「技術面」「ビジネス面」双方の視点で、「他部署やほかのサービスにどのような影響をどの程度およぼすか」を把握しておくことが重要です。まずは自分が担当するサービスと他サービスとの影響関係の全体像を把握しましょう。そのためには、各サービスの依存関係を視覚化するサービスグラフが役立ちます。サービスグラフを使って、エンジニアが自分で担当するサービスがビジネス面でどれだけ及ぼすのかを理解し、自分の専門的な役割をビジネスの視点から考えることは大切です。ビジネスやサービスが長期間にわたって中断されると、顧客からの反発や企業イメージの低下につながりかねません。企業イメージが被るダメージを軽減するためには、重大なシステム障害発生時のインシデント対応方法においてビジネス面でのニーズにも対応することが大切なのです。
エンジニアがインシデントの解決に取り組む一方で、並行して行われるべき「ビジネス面でのインシデント対応」にも焦点を当てましょう。ビジネス面でのインシデント対応とは「通常業務を緊急業務モードに移行させること」そして「外部顧客と内部利害関係者の両方とのプロアクティブなコミュニケーションを管理すること」です。
「インシデント対応」という言葉を耳にした際にまず頭に浮かぶのが、問題の理解と解決に長けた優秀なチームメンバーが揃い、SME(Subject Matter Expert, 特定分野の専門家)が顧客向けサービスのシステム障害修復に取り組むシーンかもしれません。「対応メンバーの人数」や「問題の深刻さ」に関わらず、サービスの修復が早ければ早いほどビジネスへの影響を軽減できます。一方で、スピーディなインシデント修復には事前の準備が欠かせません。
インシデントの重大度によってどのような役割が必要になるのかを事前に考えておきましょう。Sev2以上のインシデントの発生であれば、レスポンス対応の指揮をとる「インシデントコマンダー」や対応中に起きた重要なことをすべて記録する「記録係」といった役割が必要になります。
例えば、PagerDutyのインシデント対応チームには「インシデントコマンダー」「(インシデントコマンダーの)補佐」「記録係」「SME」「顧客連絡」「内部連絡」といった協業体制を組んでいます。チーム一丸となって問題解決に取り組み、迅速に解決策を導き出すための役割分担をめざしています。これらの役割は必ずしも異なる担当者が担うわけではありません。インシデントの範囲が小さければ1人が複数の役割を担うこともあります。また、事前に協業体制を整理することが重要な一方で、その役割はインシデントの規模と範囲に基づき柔軟に変更できると望ましいといえます。
インシデント対応チーム内のコミュニケーション手段・方法が重要なのは当然ともいえますが、「カスタマーサクセス」「セールス」「PR」「シニアリーダー」といったチーム外のステークホルダーへの連絡方法も重要です。インシデントの重大度レベルによって「どの部署の、どのレベルのメンバーに連絡するか」を決めておきましょう。そうした社内のステークホルダーへの通知が適切に行われない場合、社内で無用な混乱が生まれる可能性があります。
インシデント対応が無事完了したらその対応内容を振り返ることは重要です。今後同様のケース・インシデントが生じた際の解決のヒントを得ることが可能です。また、これまでの重大なインシデントへの対応方法を改めて具体的に振り返ることで事後分析をしてみることもおすすめです。
社内でレトロスペクティブを実施する際、改善に向けた徹底的な議論に必要なのが「タイムライン」「影響度合の記録」「インシデント分析」「アクション項目」「外部へのメッセージ」などの情報を整理して議論に臨むことです。こうした項目を含む詳細で正確な事後報告書があることで、ミスから学び、システムやプロセスを改善することに繋がります。
また、レトロスペクティブで最も重要とも言えるのが「チームが振り返ることに悪い印象を持たないようにすること」です。誰かを非難するのではなく、一緒に学ぶという姿勢が大切です。効果的なレトロスペクティブを実施するための参考として、こちらの記事「DevOps強化のための『セイルボート・レトロスペクティブ』とは?」もご覧ください。
レトロスペクティブ/事後分析とプロセス改善をしっかり行うことで、自社システムへの新しい発見が生まれるはずです。バグ修正などのアクションの優先度を変更すれば、影響を受けたサービスの信頼度を改善でき、その対応プロセスの改善にもつながります。また、事前準備の効率化も図れるかもしれません。「コミュニケーション方法や記録方法の改善点はないか」「自動化できるものはないか」といった確認も忘れずに行いましょう。
ここまでご紹介してきた10のチェックポイントを確認することで、「インシデント対応の改善に向けて自分たちがそれぞれどのような役割を担っているか」という技術チームの理解を少し深めることが可能になります。そして、そうしたインシデント対応の体制を絶えず改善し続けることが、インシデント対応をより効率化しシステム障害の未然予防という大きな果実へと繋がっていきます。
また、増え続けるインシデントに対して、インシデント対応チームメンバーの数・リソースが見合わないという状況は今後も続くかもしれません。そうした限られたリソースの中でシステムを運用するためには効率化が不可欠です。チーム内の業務量のバランスを改善する手段は、人的リソースを増やすことだけではありません。「インシデントの検知」「顧客への影響の防止」「問題の診断と解決」「失敗からの学び」といったことの重要性を今回の記事を通じて少しでもお伝えすることができますと嬉しいです。
PagerDutyは、そうした企業のインシデント対応体制の改善・アップデートをご支援するために、インシデントライフサイクルを通じてインシデントを一元管理することが可能なプラットフォームです。AWSやオブザーバビリティツールなど700を超えるツールとインテグレーションが可能であり、それらのツールから発せられる大量のアラートをAIが分析して、本当に対応が必要なインシデントのみを最適な対応チーム宛にエスカレーションすることが可能です。さらには、今回の記事でもご紹介したインシデント対応後のスムーズなレトロスペクティブや事後分析の支援も可能です。皆様のより効率的なインシデント対応体制の構築をぜひともご支援したいと思いますので、ぜひPagerDutyをお試し頂けますと幸いです。なお、PagerDutyの導入事例はこちらからご確認いただけます。
▼こちらの記事もおすすめ
> システム障害を未然に防ぐ「インシデント管理」とは?
> インシデント対応とは?事例から読み解く対策方法
エンジニアの燃え尽きを防ぐ秘訣とは?
一段と信頼性の高いシステムを顧客が求めるようになり、勤務時間外や夜間の対応など、技術チームへの要求も増しています。本レポートでは、19,000 社以上、100 万人を超えるユーザーで構成されるPagerDutyプラットフォームから収集したデータを基にしたシステム運用の”今”を解説!→ PagerDutyの資料をみる(無料)

この記事が気になったら




PageDuty公式アカウントをフォロー

PagerDuty
Manager, Solutions Consulting
ソリューションズコンサルティング マネージャー
PagerDuty
Manager, Solutions Consulting
ソリューションズコンサルティング マネージャー
ネットワーク機器メーカーにて、インターネット・データセンターのインフラ構築に従事した後、CDNベンダーにて主に動画・ゲーム・電子書籍サービスの拡張性ならびに信頼性向上・セキュリティ対策プロジェクトを推進。2022年よりPagerDuty株式会社にて、インシデント対応の自動化等、デジタルオペレーションのモダン化・成熟度向上を支援している。趣味は自家製スモーカーを使ったベーコン等の燻製作り。
SNS
 関連ブログ記事
関連ブログ記事
 人気記事
人気記事 検索
検索 タグ
タグ目次











