3分で分かるPagerDuty~PagerDutyだから実現できる迅速でプロアクティブなインシデント対応~
この資料では、日本企業が抱えるインシデント対応の課題を明らかにし、それを解決するPagerDutyの迅速かつプロアクティブなインシデント対応をご紹介します。


近年、金融機関や通信会社などで多発しているシステム障害。システムが1分停止すると約100万円、24時間で約10億円の損失が生じるともいわれています。システム障害が長期化し大きな損害になるケースの多くは、原因究明や復旧作業などが遅れることに原因があると考えられがちですが、本質的な課題は「システム運用監視体制」が整っていないことにあります。ますますデジタル化が進む中で、システム障害は必ず起きるものであり、ゼロにすることはできません。いざというときに適切なインシデント管理・対応ができるよう、インシデント対応のための体制や仕組みを構築しておくことが重要です。本記事では、インシデント対応の一般的な流れと、LINE社のPagerDuty導入事例から読み取れる運用体制の構築ポイントを紹介します。
目次
「インシデント(incident)」という英単語には、将来的に重大な事件に発展する可能性を含む事象や小さな事件、といった意味があります。IT分野で用いられる場合もその意味に大きな違いはないものの、インシデントのニュアンスは企業やインシデントを管理する分野によって多少異なります。例えば、ITシステム運用におけるインシデントは、「ユーザーが正常にサービスを利用できない状態」を指します。これには、ユーザーの操作ミスからシステム障害まで、幅広い事象を含みます。一方、セキュリティ関連の現場では、「セキュリティを脅かすおそれのある事象」といった意味で用いられます。よりセキュリティに特化した内容を指すため、「セキュリティインシデント」とも呼ばれます。
PagerDutyでは、インシデントを「システム障害に際して何らかの対応が必要な課題」と定義しています。また、インシデントが発生した際、システムやサービスを迅速に復旧させるための取り組みを「インシデント管理・対応」と呼びます。インシデントは「障害」と混同されることがありますが、実際は異なるものであり、障害はインシデントの要因の一つといえます。どのようなインシデントでも、発生時には迅速な対応が必要です。ITシステム運用のインシデント対応では通常、ユーザーのサービス利用の再開を優先して対応いします。例えば、システム障害が発生した場合には、一時的な対処を施してユーザーへのサービス提供を再開し、その後、本質的な障害対応にあたるといった形式です。

ここでは、IT分野でのおもなインシデントの種類と、その具体例を紹介します。実際にインシデントとして管理する対象や範囲は、企業や部門によって異なります。
・システム障害
ハードウェアやソフトウェア、ネットワーク環境などに障害が発生し、ユーザーのサービス利用が阻害されるケースです。例えば、サーバーの障害発生でメールの送受信ができない、ネットワークが遮断されてサービスにアクセスできない、といった事象が挙げられます。
・アクセス集中によるシステム負荷の増大や応答速度の低下
想定を超えるシステムへの負荷で、Webサイトやアプリの利用に支障が生じるケースです。例えば、期間限定のキャンペーンや著名人を起用したマーケティング施策を実施すると、想定よりも大幅なアクセスの増加につながることがあります。その結果、システムがアクセス集中に対応しきれず、Webサイトにつながりづらいといった事象が発生します。
・人為的なミス
ユーザーの操作に起因して発生するインシデントもあります。例えば、連続したパスワードの入力ミスで利用にロックがかかったり、ITシステムのライセンス切れでエラー表示がされたりするケースです。
・不正アクセスによる情報漏洩や改ざん
コンピュータやネットワークの脆弱性を悪用したWebサイトへの不正なアクセスにより、企業やユーザーが損害を被るケースです。例えば、Webサイトを改ざんして個人情報を流出させたり、不正アクセスして会員情報を改ざんさせたりします。
・サイバー攻撃やマルウェアへの感染によるシステム異常
サイバー攻撃によりシステムに異常が発生し、ユーザーのサービス利用やシステム操作が妨害されるケースです。例えば、大量のトラフィックによりユーザーのアクセスが妨害されたり、高度なマルウェアでシステムが乗っ取られたりします。
・落雷などによる設備の故障
自然災害の影響で発生するインシデントです。落雷や火事によって物理的にシステムやセキュリティ設備が損壊し、データの損失やサービスの停止といった事態が発生します。
・パソコンなどの情報機器・記憶媒体の紛失や盗難
人為的なミスや過失による、セキュリティ面でのインシデントです。情報機器の紛失のほか、メールの誤送信による情報漏洩、無許可での私物端末利用によるマルウェア感染などが挙げられます。
サービスが稼働していない夜間にシステム障害に対応するのはもう昔の話であり、現在は24時間365日のシステム稼働と、サービス提供が当たり前の時代になりました。その結果、システム運用においてサービスを正常に利用できないインシデントが生じた場合には、以前よりもサービスの満足度の低下や企業の信頼喪失につながりやすくなっています。
特にシステム障害のような、サービス停止をともなう重大なインシデントの発生した場合、サービス再開までの時間が長くなるほどに損失額も大きくなります。その損失額は決して小さいものではなく、企業の存続に関わるような規模になることもあります。インシデントの影響は企業の信頼損失に留まりません。あらゆるサービスがITシステムを介して提供されており、その中には医療などのミッションクリティカルな事業も含まれます。インシデントの発生によりサービスを利用できなければ、人命に関わる事態が起きる危険性もあるため、サービスの停止はもはや社会課題の一つだといえます。しかし、インシデントは外部からの攻撃や自然災害などが要因となることもあるため、まったく発生させないことは不可能です。そのため、いかに早い段階でインシデントを検知し、迅速な対応でその影響を最小限に留められるかが重要になります。
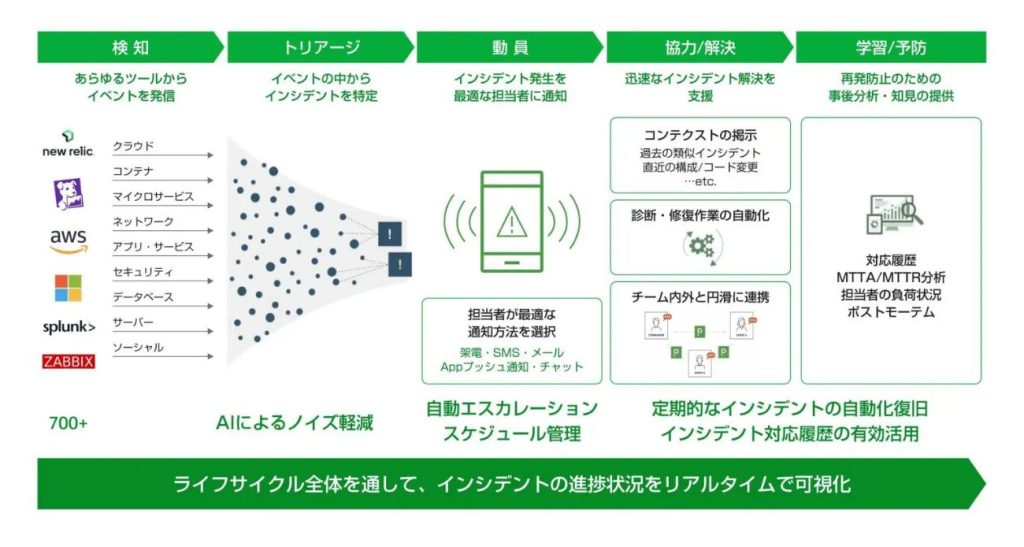
ここでは、一般的なインシデント対応の流れをご紹介します。
インシデントの検知方法は、次の2つに大きく分けられます。
・ユーザーなどの外部からの報告を元に検知するパターン
・保守作業や監視ツールのアラートなどから自社で検知するパターン
どちらのパターンで検知されても、自社でシステムの監視をしっかりと行なっておくことで、問題の切り分けがスムーズになります。監視ツールやオブザバビリティツールによってシステムの監視を行ない、異常を検知した際にはアラートが送られます。システムが複数あったり、担当部署が違ったりといった理由で複数の監視ツールを使う場合が多いため、それぞれのツールから適切にアラートが送信されるよう、設定する必要があります。一日のアラート数は会社によって異なりますが、数千~数万になる場合もあります。
トリアージとは、検知された内容に対する対応の要否と、対応が必要な場合の優先度などを判断することです。それを判断するうえでは、監視システムの誤動作や業務妨害を含む外部からの誤った報告、といったさまざまな可能性を想定しておく必要があります。
担当者は、受け取ったアラートの中からインシデント(対応が必要なもの)を特定し、システム運用担当者への通知や自動修復など、適切な一次対応を実施します。この段階では、対応の要否を判断することが優先であるため、原因の究明には取り組みません。監視センターなどで、このステップを人手で行なう場合、オペレーターは手順書(Runbook)を参照して対応を行ないます。手順書には、受け取ったアラートの内容に応じて「システム担当者に通知するかしないか」「どの担当者に電話で通知するか」等、どのような一次対応を実施すべきかが記載されています。
システムが複雑になると、この手順書の内容も複雑になります。大量のアラートに対して人手で対応すると、対応に時間がかかるうえに、時にはミスも発生します。また、トリアージには冷静かつ正確な判断が欠かせません。したがって、発生時間や場所、発生内容といったインシデントに関する情報を適切に整理することも求められます。
トリアージの結果に応じて、関係部署に連絡します。システムの運用担当者による対応が不要であれば、コールセンターなど外部からの受付部門がそのまま対応にあたります。システム運用担当者による対応が必要になった場合、そのシステムに責任を持つ担当者に通知を行ない、インシデント対応を開始します。担当者は、一般的に専用のアプリや電話・メール・チャットで通知を受けます。適切な担当者に通知する必要があるため、どのようなアラートを受け取った場合に誰に通知すべきなのかを、明確にしておくことが重要です。また、当番の担当者が対応できない場合に備えて、バックアップの仕組みも構築する必要があります。
4. 協力/解決
運用担当者がインシデントにアサインされれば、次は原因を特定し、解決するステップに入ります。インシデント対応においては、まずインシデントの影響を最小限に抑えるための措置や、別の箇所への影響を防ぐための措置を講じます。その後、調査を進めて根本の原因が判明したら、本格的な対処をします。原因を特定するための情報収集を行ない、必要であれば専門のエンジニアやベンダーなどに対応を依頼して、原因特定と復旧作業を進めます。また、影響の大きいインシデントであれば、進捗状況や影響範囲について、社内の関係者(経営者やカスタマーサービス等)にも適切に情報共有をしなければなりません。インシデントの内容によって、関係者への情報共有の適切なタイミングは異なるため、インシデントの情報統制に関する検討は事前に行なっておきましょう。
今後のインシデントの未然防止や運用プロセスの改善に向けて、「事後検討レポート(ポストモーテム)の作成」や「運用プロセスの見直し」を行なうステップです。各インシデントの対応履歴の記録とMTTA/MTTRなどのKPIを可視化し、見直しを行なうための仕組みが必要になります。また、システム運用におけるインシデントの場合は、発生から解決までの詳細な情報を、ログとして残しておくことも重要です。これにより、さらに早い段階でインシデントを検知して対応することや、同様のインシデント発生時にスムーズに対応することにつながります。各種情報を基に、同様のインシデントが発生しないように再発防止策を講じます。運用プロセスの見直しのほか、セキュリティインシデントでは、セキュリティ対策ツールの導入や従業員へのセキュリティ教育の強化といった施策が挙げられます。将来的なインシデントの発生を防ぐには、組織内での情報・教訓の共有も大切です。また定期的なレビューを行ない、インシデント対応の仕組みや体制を見直すことで、より効果的な対応が可能となります。
現代はシステム構成が複雑化し、それにともなってインシデントの発生数も増加傾向にあります。多くのインシデントに対応するために、インシデント対応の効率化の重要性が増しているのです。しかし、インシデント管理の難易度が高まっていることもあり、現場は多くの課題を抱えています。例えば、次のようなインシデント対応における課題が挙げられます。
このように、インシデント対応が非効率な状態は企業にとってリスクであり、ビジネスに悪影響をおよぼします。例えば、大量のアラート対応はエンジニアを疲弊させ、開発への取り組みやイノベーションを阻害する要因になります。また、緊急度の高いインシデントへの対応の遅れはサービスの停止時間の増加を招き、甚大な損失や顧客満足度の低下につながります。したがって、インシデント対応の効率化や迅速化に向けた取り組みは、ビジネスの継続や成功においても重要だといえます。

インシデントの発生を避けることは難しいのですが、事前の取り組みによって対応にかかる手間や時間は大きく異なってきます。ここではインシデント対応を効率良く行なうためのポイントを解説します。
より重大なインシデントへ迅速に対応するためには、優先度の判断基準を設けてインシデントレベルを振り分けられるようにしておく必要があります。その際に併せて必要になるのが、インシデントの難易度に応じた担当者の選定ルールです。どの部署にどのインシデントを引き継ぐのか、事前に明確にしておくことでスムーズな対応につながります。
表計算ソフトやチャットツールなどを使ったインシデント管理は、手軽に始められる一方、多くの手作業が発生して対応が非効率になりやすい側面があります。そこで活用したいのが、インシデント管理ツールです。インシデント管理ツールとは、インシデントに関する情報とその対応プロセスを適切に管理するためのツールです。例えば、監視ツールからのアラートを取りまとめて一元管理することや、各部門のスムーズな情報連携、対応の自動化などが可能です。インシデント管理ツールにはさまざまな種類があり、ツールによって機能の内容や対象とするプロセスが異なります。インシデント対応のプロセス全体を対象とするツールであれば、プロセス全体を見直せるほか、蓄積したデータを基に再発防止に向けた取り組みの実施にもつながるためおすすめです。
セキュリティインシデントの対策では、事前のセキュリティポリシー作成が欠かせません。セキュリティポリシーとは、組織や企業が定める情報セキュリティ対策の行動指針・方針のことです。セキュリティ対策におけるルールを定めることで、社員の裁量によって生じる不正行為を減少させ、セキュリティに関する事故の発生を抑えることにつながります。
LINE社は、多くのユーザーが利用するメッセージアプリや、決済サービスなどを提供しており、エンジニアが多数在籍しています。2016年から運用しているプライベートクラウド「Verda」では、同社がサービスを提供するにあたって必要なシステム基盤が展開されており、80名の開発者がさまざまなサービス開発やインシデント対応に関わっています。ここでは、PagerDutyの導入事例内容から読み取れる、LINE社の具体的なインシデント対応改善事例を紹介します。
「2.トリアージ」「3.動員」部分に課題があった
LINE社では、Slackの専用チャンネルに投稿されるアラートを開発者が見て、気づいたメンバーが自発的に対応していました。しかし、アラートが多いと「どれが最も重要なのか・だれが対応するのか」なのかが判断しづらく、迅速な対応ができないこともありました。
インシデント対応を、外部のMSP(マネージドサービスプロバイダ)企業に依頼する選択肢もありましたが、インシデントを検知してから担当者に通知するまでを文書でマニュアル化しなければなりませんでした。「それならコードを書いたほうが速い」と判断して、PagerDutyを使うことになりました。
LINE社では、緊急対応が必要なインシデントに24時間体制で対応するオンコール対応を、それぞれのサービス開発チームで体制を組んで実現しました。1週間あたり2人のエンジニアが各チームにつく体制をつくり、アラート発生時には電話・アラート音で担当者に通知します。担当となる頻度はチームの規模によって異なり、月に1~2回巡ってくる体制です。また、Slackに専用チャンネルを設け、PagerDutyからの通知を受けたタイミングで、APIを使ってサポート担当者のメールアドレスを返信するように環境を構築。このシステムにより、メンションする担当者を自動的に割り当てる試みを実施しました。対応内容は、別途課題管理アプリケーションと連携してチケット化することによって、「チーム内でだれがインシデント対応をしているか」など、進捗状況もわかりやすくなりました。その結果、アラートの件数も減少しています。
アラートの監視とシステム担当者への通知を外部委託すると、大量のアラートが発生した場合に適切な対応ができなかったり、担当者に通知するまでに時間を要したりすることがあります。これは、インシデントを検知してから担当者に通知するまでの手順を文書でマニュアル化したうえで、委託先が人手で対応するためです。一方、「トリアージ」「動員」を自動化するツールを活用して自社運用する場合は、アラートが発生してから担当者に通知するまでの時間を数秒に短縮することができ、通知漏れなどのミスも減らすことができます。また「トリアージ」段階で自動診断の機能を活用して、原因特定に必要な情報を収集しておけば、担当者が問題解決を素早く行なうことができます。復旧作業を自動化すれば、担当者に対応を依頼することなく、自動復旧させることも可能です。
緊急性のないインシデントで夜中に起こされるなど、一部の担当者にインシデント対応の負担が偏らないよう、アラート数や担当者ごとの通知を受けた回数・時間帯などのデータを可視化し、運用を最適化する工夫が必要です。同社の事例では、メンバーに電話がかかるようになったため、導入後の現場で戸惑いが見受けられました。しかし、インシデントの優先順位を決めてアラートを減らす仕組みをつくることで、メンバーへの電話が減るように工夫しました。さらに、各チームと対話してアラートの定義づけを行ない、部門や担当者を明確に設定しているほか、インシデントの対応中に別のコールが重ならないように体制が整えられています。
インシデント管理ツールを導入することで、エンジニアの負担を軽減し、問題解決をスピーディーに行なえます。ツールによっては「動員」部分の機能しか提供していなかったり、連携できる外部ツールが限られていたりするなど特徴が異なるため、自社に合ったものを選ぶことが大切です。
LINE社はPagerDutyを導入し、重要なアラートが迅速に開発者に届く仕組みを実現しました。また、PagerDutyのAPIを活用し、Slackとの連携により担当者にメンションを行なう仕組みの構築のほか、課題管理アプリケーションとの連携でチケット化を行ない進捗状況を記録・共有するなどして、業務効率を高めています。
「システム運用監視体制」の整備により、インシデントが発生した場合でも迅速に解決に導くことが可能です。日々のシステム運用状況を可視化し、プロセスや体制を継続的に改善することができれば、インシデントの発生を最小限に抑え、エンジニアや関係者がインシデント対応以外の本来の業務に注力できるようになります。PagerDutyを導入することで、本記事で紹介した「トリアージ」「動員」部分を含め、インシデントライフサイクル全体を効率化し、工数削減と迅速なインシデント解決を実現できます。これからインシデント対応の体制・プロセスを整備しようとしている方は、ぜひ参考にしてください。インシデント対応のための体制・プロセスを適切に構築することが、迅速で効率的なインシデント対応につながります。自社の状況やニーズに合わせて、適切な体制・プロセスを支えるツールを選択しましょう。
▼こちらの記事もおすすめ
システム障害を未然に防ぐ「インシデント管理」とは?
インシデント対応を効率化する「10のチェックポイント」
この資料では、日本企業が抱えるインシデント対応の課題を明らかにし、それを解決するPagerDutyの迅速かつプロアクティブなインシデント対応をご紹介します。

この記事が気になったら




PageDuty公式アカウントをフォロー

PagerDuty
Manager, Solutions Consulting
ソリューションズコンサルティング マネージャー
PagerDuty
Manager, Solutions Consulting
ソリューションズコンサルティング マネージャー
ネットワーク機器メーカーにて、インターネット・データセンターのインフラ構築に従事した後、CDNベンダーにて主に動画・ゲーム・電子書籍サービスの拡張性ならびに信頼性向上・セキュリティ対策プロジェクトを推進。2022年よりPagerDuty株式会社にて、インシデント対応の自動化等、デジタルオペレーションのモダン化・成熟度向上を支援している。趣味は自家製スモーカーを使ったベーコン等の燻製作り。
SNS
 関連ブログ記事
関連ブログ記事
 人気記事
人気記事 検索
検索 タグ
タグ目次












