公式資料
公式資料
自動化ROI測定ガイド
本ガイドでは、現在のビジネス状況から収集すべき「ベースとなる指標」から「自動化対象のワークフローの利点」まで、企業が推進すべき「自動化プロジェクトのROI・ビジネス価値」を効果的に計測する方法を詳しく解説。
社内の業務プロセスの自動化を検討する皆様必見です!→ PagerDutyの資料をみる(無料)


企業におけるチームリーダーたちの多くは、近年の経済状況における組織運営の鍵が「バランスの取れた長期的な成長」であることをよく理解しています。しかし、その実現は決して簡単ではないこともまた同時に理解しています。そうした多くのリーダーは今、「効率の最大化」「付加価値の高い仕事をしてくれる優秀なチームの確保」「顧客の期待を裏切らない洗練された優れたデジタル体験」を実現する方法を模索しています。
これらを実現する解決する近道となるのが、「業務を自動化できないだろうか?」「本当にその領域の専門家 (SME: Subject Matter Expert) が必要だろうか?」と自らに問い続けることかもしれません。業務を自動化できれば、その時間やコストを戦略的な取り組みに費やせるためです。自動化できる対象や要素が多々ある中でも、高いROIを期待できるのが「インシデント対応の自動化」です。インシデント対応の自動化は、その必要性・重要性を感じつつも「どこから手を付ければよいのかわからない」という方も多いかもしれません。またインシデント対応のプロセスを自動化することは、非現実的だと思われるかもしれませんが…実は可能です。「エンドツーエンドのイベント駆動型自動化」は導入できる領域がとても広く、無限大と言っても過言ではありません。そこで本記事では、より効率的なインシデント対応の実現に向けた自動化の導入や拡張方法をわかりやすく解説します。
目次
企業を取り巻く現代のシステム環境は複雑さを増しており、それにともなってインシデントの発生件数は増加傾向にあります。その一方で、ユーザーにとって「24時間いつでもサービスを使えること」はもはや当たり前になっているため、インシデント対応によるサービスの停止を長く待ってはくれないともいえます。システム障害による顧客満足度の低下を避けるためにも、迅速なインシデント対応による「平均修復時間(MTTR)の短縮」や「顧客に影響を与える前のインシデント解決」は重要な取り組みだと言えます。しかしながら、インシデント対応の現場では多くの手作業・マニュアル作業が存在します。手作業はヒューマンエラーの発生リスクとなるうえに、ノウハウを属人化させて対応品質のばらつきを生み出します。したがって、迅速なインシデント対応を阻害する主な要因の一つともいえます。
そこで必要となるのが、インシデント対応の自動化です。自動化により繰り返し発生する手作業からエンジニアが開放され、重大なインシデントの解決に集中できる環境が整えることができれば、平均修復時間(MTTR)の短縮のほか、エンジニアの負担減による燃え尽きの回避、インシデントの早期対処による顧客満足度の向上など、さまざまな良い変化を期待することができます。
「イベント」とは、モニタリングツールから発せられる障害の兆候に関する警告サインを指します。モニタリングシステムやオブザーバビリティツールで必要とされる警告の設定は企業によって異なるため、必要なサービスのパフォーマンスに関する情報をチームに通知するために、イベントを作成する必要があります。そして「イベント駆動型自動化」とはつまり、イベントの発生をきっかけとして開始される自動処理になります。
例えば、一般に外部からのデータを取り込む際には、正規化とエンリッチメント(既存のデータをわかりやすく有用にする工程)が必要です。このプロセスを自動化することで、イベントデータを理解しやすい形式に自動で変換でき、インシデント発生時により迅速に対応できるようになります。そのほかにも、自動化によってイベントデータをアラートとして作成し、コンテキストを追加して適切なチームや担当者に振り分けられるため、インシデント対応のプロセスをスムーズに開始できます。さらに高度な実装になると自動診断や自動修復が開始され、問題がインシデントと判断される前に解決されることがあります。
また「エンドツーエンドの自動化」とは、必要に応じてインシデント対応のライフサイクルのすべてを自動化することです。頻繁に発生する問題であれば、人が介在することなく解決できます。これにより、一部のインシデント対応からエンジニアを解放することが可能です。つまり「エンドツーエンドのイベント駆動型自動化」とは、「発生中のイベント」を「解決済みのインシデント」に自動に変換することができる画期的なイノベーションを指しているとご理解いただければと思います。
エンドツーエンドのイベント駆動型自動化の実施は、多くのメリットをもたらします。その影響は幅広く、ネットワークオペレーションセンター (NOC) からサポートチーム、さらにはシステム開発チームにまでおよびます。それぞれのチームにどのようなメリットがあるのか、個別に見ていきましょう。
モニタリングの設定が原因で、インシデント対応の最前線にいる担当者は検知されるさまざまな内容のアラートをすぐには理解できないことがあります。これは「正規化されたデータがなく重要なアラートとそうでないものを担当者自身で判断する必要がある」ためです。この重要度の判断作業には、非常に時間がかかります。このような環境において、エンドツーエンドのイベント駆動型自動化を導入することで、NOCが受信したイベントデータを自動で正規化し、イベントの内容に応じて適切な部署・担当者に振り分ける基準をグローバル規模で設定できるようになります。さらに、NOCが担当する問題を簡単にトリアージできます。この「L0(レベルゼロ)」の段階から自動化を導入することによりNOCはより効率的に問題を解決できるようになります。
SREチームは、組織内で「自動化の管理者」の役割も担っていることが少なくありません。ときには、自動化の構築、保守、スケーリングを担当したり、作業の効率化を目指すほかのチームのコーチ役を務めたりすることもあります。SREチームでエンドツーエンドのイベント駆動型自動化が実現されれば、イベントの変換とルーティング(適切な部署・担当者への振り分け)を設定し、イベントの全行程を自動化すること、また、自動で解決できるインシデントには人が対応せずに済むように、自動修復を構築することも期待できます。
MIM (Major Incident Management)チームは、インシデント対応の司令塔となったり、複数の部署の意見をまとめて企業としての対応を一元化したりする役割を担います。この役割をスムーズに遂行するには、自動化によって重大インシデントを早期に検知し、ただちにルーティングすることが効果的です。さらに、自動診断でインシデントを入力し、イベントデータを正規化する必要もあります。このようなMIMチームでの自動化は、迅速な対応による損失の低減といった大幅なコスト削減につながるでしょう。
エンジニアリングチームは、サービス開発を通してイノベーションを推進するうえで必要不可欠な存在です。そのため、チームが火消し作業に多くの時間を使っていては本来の業務に差し支えます。そこでエンドツーエンドのイベント駆動型自動化を導入すれば、インシデントは常に適切なチームに振り分けられ、対応が必要な通知だけを受け取れるようになります。さらに、既知の問題には自動修復を行なうことで、付加価値の高い業務により時間を費やせることが期待できます。
サポートチームにエンドツーエンドのイベント駆動型自動化が導入されれば、平均修復時間 (MTTR) が短縮され、インシデント数も低減できます。また、顧客に影響を与える恐れのあるインシデントも、エンジニアリングチームのサポートを必要とせず自動修復を使って解決することが可能です。最初から適切なデータと適切なチームでインシデントに対応するため、システム障害により感情的になった顧客に対応するケースが減り、メンバーの抱える精神的なストレスも減らせることを期待できます。
自動化をスムーズに進めるための戦略を立て、その効果を検証する必要があります。また多くの場合、エンドツーエンドのイベント駆動型自動化を一気に導入するやり方はおすすめできません。非常に多くの変化が一度に起きてしまい、ほかの重要な業務に影響が出ても、導入作業を止められないからです。
そこで推奨される導入方法が「Crawl-Walk-Run(ハイハイ – 歩く – 走る)」という無理のないペースで社内で自動化を進めるアプローチです。この方法では、業務を進めながら導入効果を段階的に確認でき、他部署からの賛同も得やすいためおすすめです。また、すぐに目に見える効果が得られ、特にノイズレベルや平均修復時間 (MTTR) 等の改善に大きく貢献します。そのため、このアプローチを活用し、多くの企業が自動化の導入に成功しています。詳しい「Crawl-Walk-Run」アプローチについては、こちらの記事「『インシデント対応の自動化』に企業が取り組むための3ステップ」も参考にしてください。
ここでは、エンドツーエンドのイベント駆動型自動化を実現するための「3つの自動化ステップ」をご紹介していきます。すぐに効果を出したい企業におすすめなのが、インシデント対応の負荷を軽減する「アラートノイズの抑制」と「通知の一時停止」です。これらは自動化のなかでも比較的実装しやすく、インシデント対応のアラートノイズによる疲れを簡単に軽減できます。一つずつ見ていきましょう。
アラートノイズの抑制とは「アラートがインシデントとして通知されることを抑制するもの」です。PagerDutyでは、インシデントが「suppressed(抑制済み)」ステータスのアラートになります。PagerDutyの「AIOps」ユーザーの利用データによると、ノイズ削減の50%がアラート抑制の効果によるものでした。このことからも、重要ではないイベントを対象にして幅広くルールを設定すれば、インシデントの発生量をスピーディーに低減できることがわかるでしょう。例えば、PagerDutyの開発チームでは受信するアラートが一定数に達するまでイベントを抑制しています。その後、アラートが一定数を超えたタイミングで抑制をオフにし「イベントオーケストレーション」機能によりインシデントの作成を開始できるようにしています。
通知の一時停止とは「ユーザーが事前に定義した期間内において、インシデント発生の通知を一時停止し、その期間が終了したあとは通常通りインシデントを通知すること」です。この自動的な通知の一時停止は、明確に定義された条件を持つ特定のインシデントに対してフラグを立てる際にも適しています。また、閾値やインシデントの停止期間といった条件を設定することも可能です。例えば、あるお客様の場合、CPU使用率が一定の高さを超えた場合に通知を5分間一時停止し、5分以上続くときはインシデントを作成するといった形でしています。
Step 1でノイズが削減され通知が一時停止されたあと、次に重要になるのが「できる限り有用な情報にすること」です。対象となるのは、チームが対応するイベントやアラート・インシデントなどで、ここで必要になるのが「エンリッチメント」です。
イベントのエンリッチメントにより、イベントインジェスト時にセキュリティイベント情報を標準的な形式であるCEFフィールドに適用できる形で書き換えたり、フィールドを新規作成してイベントをカスタムディテールフィールドに保存したりできます。これで、担当者はインシデントに関連する背景情報を入手しやすくなり、トリアージを迅速化できます。また、イベントデータを正規化することで、チーム間の認識のズレがなくなります。例えば、診断とモニタリング結果をもとにカスタムディテールを作成する企業は、フィールド結果を呼び出しスクリプトと併せて読み込むことが可能です。
イベントがアラートとして認識されると、ユーザーはアラートの重大度を設定できます。そして、アラートの重大度に応じてエスカレーションポリシーを適用します。適切な重大度でインシデントをトリガーし、適切なエスカレーションポリシーでルーティングすることが大切です。例えば、支払いなどの収益に影響する特定のサービスに関係するアラートは「Sev1(最大の重大度)」として割り当て、優先度の低いサービスは、すべてのアラートを「Sev3」または「Sev4」として割り当てます。
インシデントエンリッチメントにより、担当者はインシデント発生時の優先順位とメモの設定が可能です。メモを通じて担当者はインシデントの根本原因を把握できるだけでなく、ナレッジベースの記事や社内Wiki、対応マニュアルを作成することも可能です。例えば、インシデントエンリッチメントを活用して、自動解決できないインシデントを指摘する指示を追加し、さらに標準作業手順書(SOP)やナレッジベースのリンクを提供することにより、担当者のオンライン作業を迅速化できます。
ここまで見てきた「ノイズ低減、アラートの一時停止、イベントやデータ、インシデントのエンリッチメント」が完了すると、自動化による診断結果の収集や、実証済みの方法を使ったインシデントの解決が可能になります。これを実現する方法の一つとして挙げられるのが「Webhook(ウェブフック)」の活用です。Webhookでは、インシデント作成時にトリガーされるカスタムヘッダーとペイロードの本文フィールドを設定できます。診断が目的の場合、担当者は手動でプロセスを実行することなく、必要な情報を自動で収集できます。自動修復が目的の場合は、人の手を介さずにインシデントを解決することも可能です。どちらのケースも平均修復時間(MTTR)を短縮し、インシデント対応チームと解決を待つ顧客、その両方のストレス軽減につながります。
もう一つの方法は、PagerDutyの「Automated Incident Resolution」を使用することです。Automated Incident Resolutionは、ぺイジャーデューティ製品の一つ「PagerDuty Process Automation」の一部で、インシデントの一次対応者自身が、専門知識を利用してインシデントの「トリアージ、診断、修復」を行なえるようになります。インシデントが作成された際、PagerDutyのオートメーションジョブは自動でも手動でも起動することが可能です。以前は専門スタッフしか扱えなかった自動化の修正・追加といった業務も、ジョブテンプレートとプラグイン インテグレーションがすでに組み込まれているため、一次対応者が専門知識に基づいて対応できます。Automated Incident Resolutionは、ファイアウォールの内側またはVPCの内部に配備されたRunner経由で制作基盤と接続されています。Runnerはローカルオートメーションステップを実行し、暗号化された接続を中央の自動化環境に提供します。
ここまできたら、いよいよ「Run(走る)」ステップに進みましょう。成果はあとから少しずつ見込むことができます。エンドツーエンドのイベント駆動型自動化のスピードを緩めないためにも、自動化が生み出す価値を組織内部で示していくことが重要です。「定性的」「定量的」のそれぞれの側面で価値を示す方法をご紹介します
「定性的価値」は曖昧で理解しにくいものかもしれません。数値やKPIには示されませんが、最初に自動化の成果として表れる兆候の一つだと言えます。なぜなら、チームは「業務量の適正化」「ワークライフバランスの改善」「割り込みの削減」に奮闘しており、付加価値のある仕事に時間を割くことを望んでいるからです。業務量が適正化されれば、仕事への意欲が高まり、さまざまな良い影響を生み出すでしょう。これを数値で示すことは簡単ではありませんが、成果の度合いを測る方法をいくつかご紹介します。
自動化が導入されたチームと、そうではないチームの「離職率」を比較します。インシデントが頻出するチーム間での比較であればその違いは顕著に出ます。離職率が5〜10%改善されただけでも、代替スタッフの採用やトレーニングにかかるリソースと時間的なコストの削減につながります。
転職のチャンスは誰にでもあるため、離職者をゼロにすることはできません。だからこそ、退職者面接で退職理由を知ることが重要です。退職者面接の内容に、自動化を含むプロセスの質問があるかどうかを人事部に尋ねてみるのも良いかもしれません。さらに、退職者面接で出た意見を、退職者の詳細を伏せてシェアしてもらえないか依頼してみる方法もあります。
自動化の取り組みによって社員の働きやすさや意欲が向上したかどうかについて、社員の考えを定期的に確認してみましょう。社員の意識調査を行なう頻度を見直し、自動化の取り組みに関する質問を加えて、社員の気持ちに耳を傾けてみてください。その気持ちを四半期ごとに比較するだけでも成果を測ることにつながります。
測定やデータ収集を用いて自動化の導入効果を簡単に示せるのが定量的な指標です。定量的価値は、インシデント対応におけるエンドツーエンドのイベント駆動型自動化のチームへの貢献度をわずか数週間で調べられるため、定性的評価よりも素早く効果を測定することが可能です。おもな定量的指標をご紹介します。
エンドツーエンドのイベント駆動型自動化を進めているサービスの「MTTR(平均修復時間)」を調べてみましょう。前月のMTTRと比較し、自動化導入による改善の程度をチェックします。データの結果を歪める可能性のある重大インシデントだけでなく、季節によるトラフィックや利用パターンの変動なども考慮してください。その改善の割合を自動化を進めていない類似サービスと比較すると、MTTRの値の変化を測ることが可能かもしれません。
自動化が適用されているサービス数でかなり大ざっぱではありますが、おそらく最も簡単な測定方法です。自動化の取り組みを開始する以前と比較して、自動化されたサービスの数はどれほど増えたでしょうか。また、時系列での数の増え方にも着目し自動化を進めるスピードを以前と比較してみると、新たな発見があるかもしれません。
過去のインシデントで発生したSLAペナルティを調べます。自動化の導入が進むにつれて、SLAペナルティが減少し、よりエンドツーエンドのイベント駆動型自動化が進むという相関関係が見られるのではないでしょうか。集めたデータをチームやステークホルダーと共有し、周りを巻き込んで社内における自動化の推進力を維持しましょう。周囲のサポートが多いほど、高いROIが見込めます。また、外部企業のサポートを受けることも検討してみてください。企業が自動化への投資を強化することは、業界全体が助け合い成長する仕組みを作ることにもつながります。
ここまでご紹介してきたインシデント対応の自動化を進めるにあたり、PagerDutyの「Operations Cloud」は、大きな影響をおよぼす緊急インシデントが突然発生しても、より迅速かつ少ないコストで解決できるようサポートします。そして、PagerDuty Operations Cloudの一部である「PagerDuty AIOps」は、ノイズを減らし、効率的なトリアージで適切なアクションを実行します。これにより、インシデント対応の煩雑で多岐にわたる業務プロセスから、人手による作業や反復作業を取り除けるようチームをサポートします。

カスタマイズされたダッシュボードを表示し、サービス全体の運用状況を包括的かつリアルタイムに把握できます。また、このダッシュボードによりチームはシステム環境の状況を一目で把握して、運用の健全性を素早く理解できます。
大量に発せられる監視ツールのアラートから、対応不要なノイズとなるアラートを可能な限り低減します。ユーザーの行動に基づいて学習・適応する機械学習モデルや独自のロジックを用いることで効果の高いノイズ削減を実現します。
過去のインシデント情報や関連性のあるインシデントをもとに、根本原因を特定するためのヒントを得られます。また、状況に即した情報や機械学習から導かれた相関関係に基づき、最近行なわれた変更とインシデントとの関連性を把握できます。
リアルタイムのイベント処理を自動化して、最適なアクションをトリガーできます。また、サービス内やサービス間での複雑なロジックを作成できるので、エンドツーエンドでの自動化が実現し解決までの時間を短縮できます。これにより、担当者の負担は軽減され、より付加価値の高い業務へと注力できるようになります。これらの機能は、機械学習や生成AIによって使い続けるほどに最適化され、自動化によってインシデント対応をより迅速化させます。また、監視ツールやコミュニケーションツール、ITSMツールなどの各種ツールと連携し、最適なインシデント対応プロセスを実現します。
さらに、PagerDuty AIOpsでは、長い実装期間や継続的なメンテナンスを必要としません。これまで、ROI400%以上のケースをはじめとする、業界最高クラスの結果を出し続けています。PagerDuty AIOpsは、機械学習と自動化で人手による業務を取り除き、お客様の業務を最適化します。また、PagerDuty Operations Cloudを使用してPagerDuty AIOpsをお客様の重要システムに組み込むことで、緊急業務が迅速化し、インシデント対応が強化されていくでしょう。
同社ではPagerDutyAIOps活用により、月間10,000件ものアラートが1,000件程度に減少しました。また、平均確認時間(MTTA)は3~5分、平均修復時間(MTTR)は2時間15分を実現しており、クリティカルではないアラートへの対応時間は月40時間ほど削減しています。
「本当に対応が必要なアラートだけを、電話やメール、Slackなど、緊急度に応じて個人が設定した最適な通知手段で受け取れます。開発委託先に依頼していた設定作業も、9割方は社内で行なえるようになり、アラートの発生状況についてチーム内で共通認識を持てるようになりました」
「UIが直感的でわかりやすいので、組織再編にともなう担当者の引継ぎも速やかに行なえました。学習コストを抑えられるだけでなく、スピード感も以前とはまったく異なります」
効率化や迅速化といったPagerDutyの効果を実感頂いています。事例の詳細については以下のページを参照してください。
Hyland社のクラウド・インフラストラクチャ・エンジニアであるBrian Long様に頂いたPagerDuty導入後の声をご紹介します。
「PagerDutyのGlobal Event Orchestration(グローバル・イベント・オーケストゥレイションズ)は、IT業務とコストを最適化するために、イベントルーティングプロセスを効率化し、拡張性を持たせるのに非常に役に立ちました」
「Global Event Orchestrationを使うことで、通知から『解決済み』の条件を検出できたので、これまで条件設定する必要があった場所の数が3分の1に減りました。設定作業が大幅に減った分、イノベーションに集中する時間を確保できるようになりました」
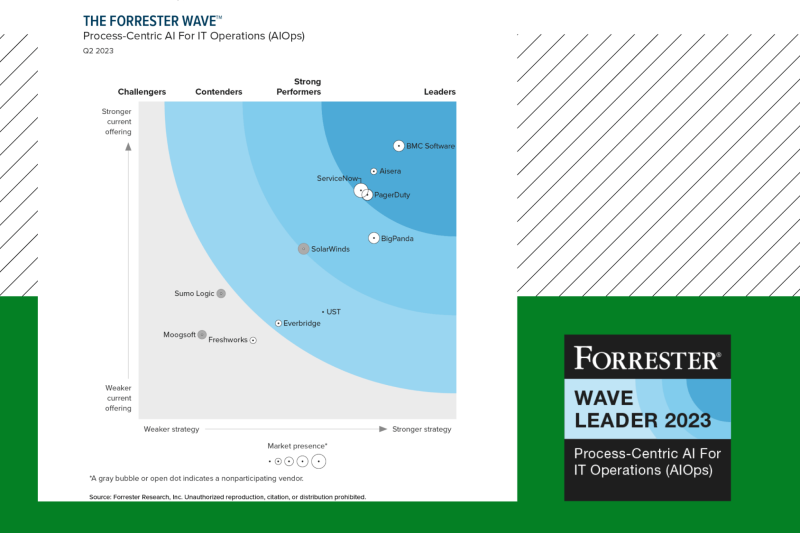
最後に、Forrester社からもPagerDutyの卓越性についてご評価を頂いています。『The Forrester Wave™: Process- CentricAI for IT Operations (AIOps), 2023』においてPagerDutyはリーダー企業に選出されたことに加えて次のようなコメントを頂いています。
「PagerDutyのイベントノイズ削減を高く評価したユーザーは、イベントインテリジェンス機能を『非常にパワフル』と述べています。PagerDutyは、多様なテクノロジーの導入を続ける企業や、自動化による作業の効率化に向け、共通プラットフォームの統合が必要な企業にとって最適と言えます」
エンドツーエンドのイベント駆動型自動化を導入すると、インジデント業務の大幅削減や対応時間短縮の実現を期待できます。その結果、より重要度の高い業務に時間をかけられるため、システム開発などお客様にとってより付加価値の高い業務にリソースを注力することが可能になります。ぜひこの機会に、エンドツーエンドのイベント駆動型自動化を検討してみてはいかがでしょうか。
とはいえ、インシデント対応の自動化を構築し、企業全体に拡大・浸透させることは決して容易ではなく、多くの課題に頭を抱える可能性があります。私たちに、この社内における自動化の推進にともなう課題解決をぜひサポートさせてください。
特に「PagerDuty AIOps」は、AIによる学習と強力な自動化で革新的なインシデント管理を実現します。インシデントへの対応時間を削減できるため、エンジニアはシステム開発やイノベーションへの取り組みにより集中できるようになります。また、AIOpsをはじめとしたPagerDutyの自動化に関する機能を使うことで、自動化を担当するチームや自動化のスケールを担うSREチームの負担軽減が可能です。ぜひ、日本におけるPagerDutyの導入事例にて、PagerDutyのさまざまな効果をご確認ください。また、本ブログでご紹介した「エンドツーエンドのイベント駆動型の自動化」の詳細ついては、こちらのホワイトペーパー(英語)からご確認いただけます。ぜひダウンロードの上ご一読ください。
▼こちらの記事もおすすめ
「DevOpsにおけるE2Eテスト」顧客体験を高める重要ポイント解説
本ガイドでは、現在のビジネス状況から収集すべき「ベースとなる指標」から「自動化対象のワークフローの利点」まで、企業が推進すべき「自動化プロジェクトのROI・ビジネス価値」を効果的に計測する方法を詳しく解説。
社内の業務プロセスの自動化を検討する皆様必見です!→ PagerDutyの資料をみる(無料)

この記事が気になったら




PageDuty公式アカウントをフォロー
 関連ブログ記事
関連ブログ記事
 人気記事
人気記事 検索
検索 タグ
タグ目次