 を14日間無料で試してみる
を14日間無料で試してみる
700以上ものツールと連携。システム障害を自動的に検出・診断するだけでなく、適切な障害対応メンバーをアサインし、デジタル業務全体の修復ワークフローを自動化します。


2025年10月20日、AWSのUS-EAST-1リージョンで発生した大規模障害は、インターネット全体に波及し、広く利用されているSaaS、メッセージング、会議システム、クラウドインフラプロバイダーに影響を与えました。この出来事は、クラウドがいかに堅牢であっても障害と無縁ではないこと、そしてインターネットの中核が揺らぐとき、その影響がどこまでも波及することを改めて思い知らせてくれました。インシデントは「起きるかどうか」ではなく「いつ起きるか」の問題です。組織の規模や投資額に関わらず、どんな組織も無傷ではいられません。
PagerDutyは、運用の可視性を守る最後の砦という特別な立場にあります。システムが故障したとき、私たちのプラットフォームは、チームが何が問題なのか、どう対処すべきかを確実に把握できるようにします。今回のインシデントでは、私たちのコアとなるインシデント通知機能は正常に動作し続け、インフラとエンジニアリングチームは下流への影響を最小限に抑えるため、迅速で的確な行動を取りました。
目次
東部時間午前3時直前、PagerDutyは通知の失敗率の上昇を検知しました。当初は内部の認証関連の問題と推測されましたが、すぐにその可能性は排除されました。状況が展開するにつれ、これが上流プロバイダーで発生した大規模なイベントであることが明らかになりました。私たちの内部「インターネット気象」ダッシュボードは、複数のアカウントで通知トラフィックが通常と異なる急増を示しており、広範囲に影響が及んでいることを示唆していました。これは、ステータスページに表示される前に重大なインターネット障害が発生していることを特定する、信頼性の高いシグナルとなっていますが、根本原因までは教えてくれません。
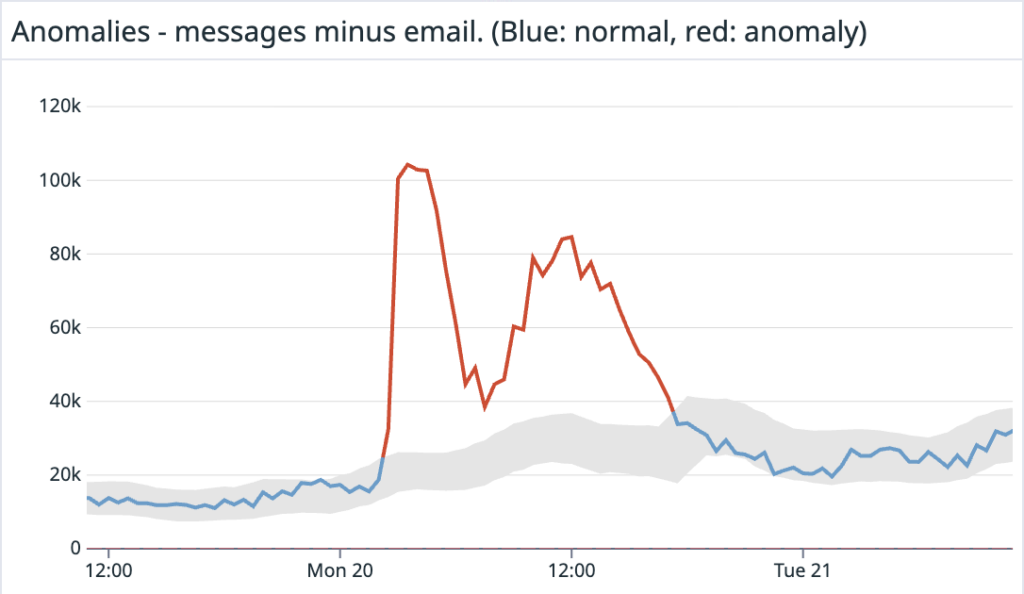
インシデントが進行するにつれて、イベント、インシデント、通知の発生率が増加しているのを観測しました。通常、北米の大部分では夜間は低トラフィック期間となるため、イベントとインシデントのトラフィックは安定したベースラインを保ちます。しかし、下のグラフが示すように、インシデントの開始直後にトラフィックは通常の少なくとも3倍に跳ね上がりました。私たちの側では、東部時間午前2時52分に最初の兆候が現れました。このような増加は、広範囲にわたる問題が発生していない限り、極めて異常です。以下は、インシデント初期段階のトラフィックレベルと前週同時期との比較です。
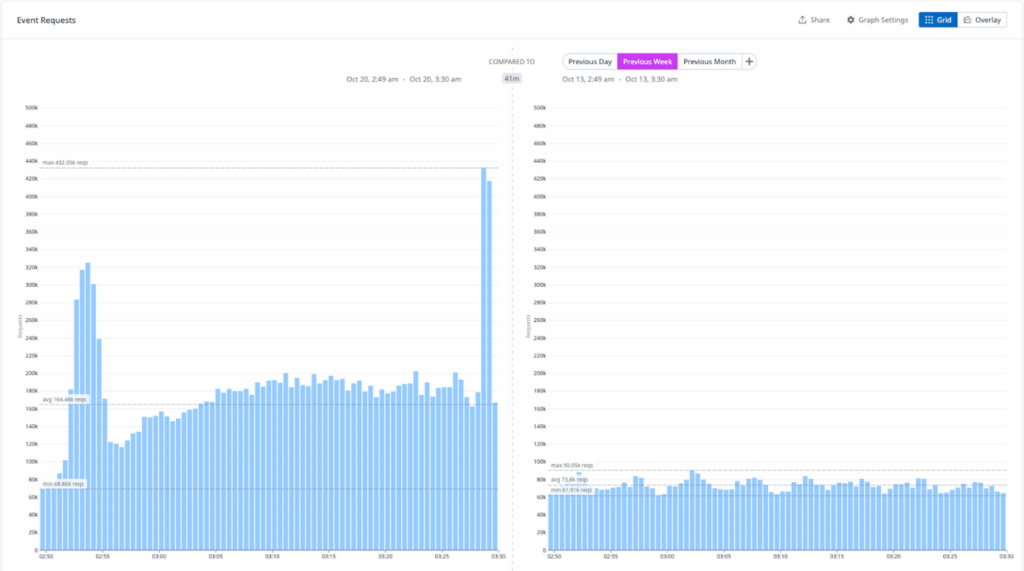
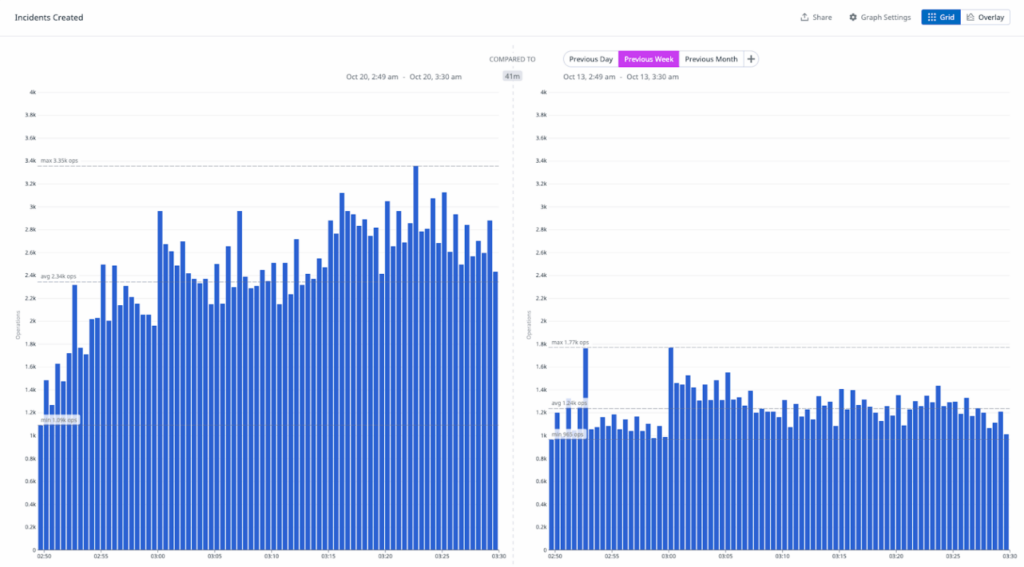
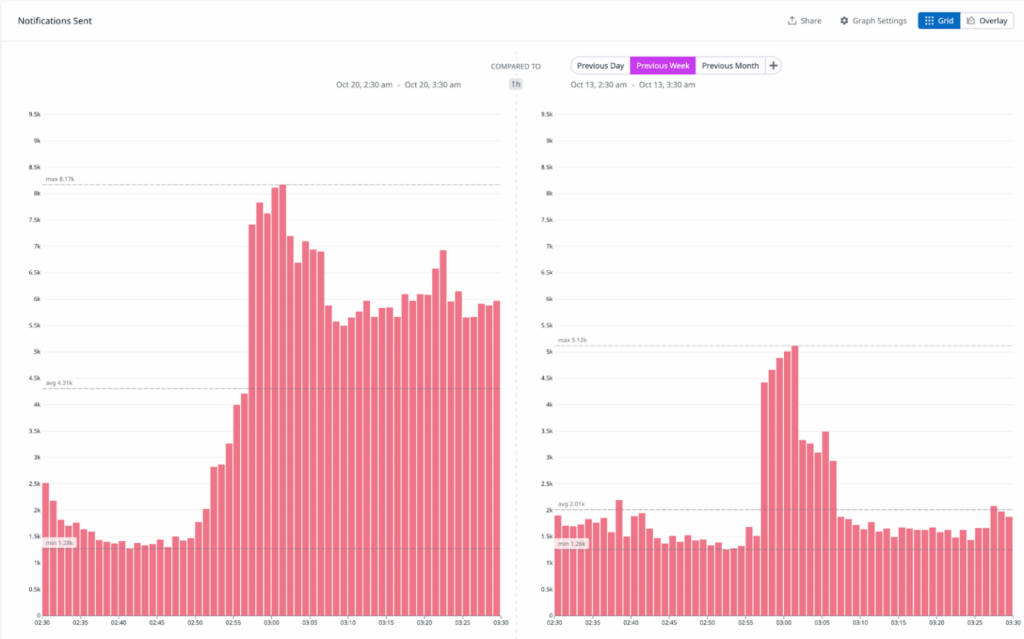
メッセージングや会議プラットフォームを含む複数のサードパーティサービスが、パフォーマンスの低下や完全な停止を報告し始めました。この問題の中心がAWS US-EAST-1であることが明白になりました。
私たちのインシデントパス通知(音声、SMS、モバイルプッシュ)、つまりリアルタイムの運用対応のライフラインは安定を保ちました。しかし、インシデントの外部影響に対応してルートを調整する介入が必要でした。
最も重大な影響は、そのリージョンでホストされている数個のPagerDutyの非中核サービスに集中しました。特に
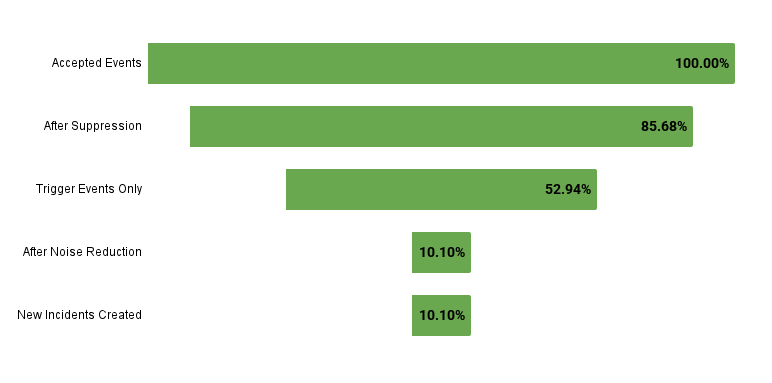
最も影響が大きかった12時間の間、私たちのプラットフォームではこのような数字が出ていました。
私たちの重複排除機能とEvent Intelligenceによるノイズ削減機能は、オンコールチームが際限ないアラートの嵐に襲われることを防ぐという点で、その真価を発揮しました。
私たちの特別な立場から、リージョン全体のクラウド障害時のインターネットの脆弱性を浮き彫りにする、インフラとコミュニケーションレイヤーの動作の急激な変化を観察しました。
プロバイダーのレイテンシと障害の急増
米国とインドで音声とSMSのレイテンシとリトライが急増し、キャリアルートが劣化しました。最悪の経路を避けるため、地域ごとにプロバイダー間でトラフィックの重み付けを調整しました。
チャットと会議の遅延
チャット通知でリトライと順序の乱れた配信が発生しました。上流プロバイダーの障害により、会議システムとの統合が初期化に失敗しました。
オブザーバビリティの劣化
クラウドでホストされているテレメトリツールがAWSの問題の影響を受け、メトリクスとイベントの可視性が制限されました。状況認識を維持するため、内部(セルフホスト)のダッシュボードに依存しました。
顧客全体への広範な影響
このインシデントの開始時、すべての主要な製品側面で急激な増加が見られました。
インシデント対応プレイブックが迅速に発動されました
インシデントが展開するにつれて、Slackで迅速に調整を行い、状況が悪化した場合に備えて代替コミュニケーションチャネルも準備しました。私たちのインシデントコマンダーは、私たちが頼っているサービス自体が問題を抱えている可能性があるこのような瞬間のために特別に設計された、バックアップコミュニケーション手順の訓練を受けています。興味深いことに、SREエージェントは、過去6か月間でまれにしか観察されなかった新しい異常なパターンを最初に警告したシステムの一つでした。これにより、「インターネット気象」ダッシュボードで相関付けていたデータが確認されました。
製品のパフォーマンスに関する最新情報を顧客に提供し、適切に対応できるよう、ステータスページに定期的な更新を投稿しました。その際、サードパーティへの言及や責任転嫁を避けることを心がけています。使用するサードパーティとそれらへの依存度は私たちが決定しており、これらが劣化したときの顧客への製品体験への影響は私たちが責任を負うものです。
一部のサードパーティ監視およびメトリクスプラットフォームを含む主要なオブザーバビリティベンダーが劣化したため、リスクを軽減するためデプロイパイプラインを即座に凍結しました。可視性が低下すると、小さな変更でも不確実性を増大させる可能性があります。目標はシンプルでした。テレメトリを再び完全に信頼できるようになるまで、安定性を維持することです。
私たちの通知システムは、複数のプロバイダーを使用し、それらを横断して配信をリトライするように構成されています。これらは、配信先地域ごとに冗長性と配信可能性を最適化しています。このインシデント中、特に米国とインドで障害のあるプロバイダーから動的にトラフィックを再ルーティングし、通知配信を安定させました。
イベント取り込み、インシデント作成、エスカレーション、オンコール通知が動作し続けるよう、コアアラートの安定性を優先しました。
このインシデントは重要な真実を浮き彫りにします。インターネットは共有依存関係であり、プロバイダー、リージョン、サービスのいずれも孤立して動作していません。US-EAST-1のようなコアリージョンがつまずくと、波及効果はデジタルスタックのあらゆる層に広がります。監視、メッセージング、コンピュート、そしてその先まで。
最も重要なのは、障害を避けることではなく、迅速かつ効果的に対応することです。PagerDutyでは、より広範なエコシステムが不安定な場合でも、最も重要なワークフローを保護するようにレジリエンス戦略を設計しています。
しかし、ここにはアカウンタビリティについてのより深い教訓があります。
エンジニアリングリーダーとして、私たちは皆、意図的にアーキテクチャと依存関係の決定を下します。これらの決定には所有権が伴います。上流の依存関係が失敗したとき、正しい質問は「誰が失敗したか?」ではなく、「どのように設計したか?」そして同様に重要なのは「次回は何を変えるか?」です。
障害は信頼の連鎖全体をテストします。クラウドでホストされたオブザーバビリティツールが劣化したとき、私たちは別のリージョンのセルフホストテレメトリに依存し、可視性が回復するまでデプロイメント/システム変更を凍結しました。
これは、観測に使用するシステムは運用に使用するシステムに決して依存すべきではないという原則を強化しました。私たちはこれを“church-and-state” モデルと呼んでいます — ダッシュボードが暗くなっても、対応者が自信を持って行動できるよう、オブザーバビリティとインシデント対応の間に明確な独立性を維持することです。
テクノロジーは障害を起こす可能性がありますが、リーダーシップは故障してはいけません。このイベント中の私たちのアプローチは、10年以上にわたって私たちが構築し、リードする方法を定義してきた同じ原則を反映していました
700以上ものツールと連携。システム障害を自動的に検出・診断するだけでなく、適切な障害対応メンバーをアサインし、デジタル業務全体の修復ワークフローを自動化します。
この記事が気になったら




PageDuty公式アカウントをフォロー
 関連ブログ記事
関連ブログ記事
 人気記事
人気記事 検索
検索 タグ
タグ目次













