 公式資料
公式資料
「デジタルオペレーションの現状」独自調査レポート
エンジニアの燃え尽きを防ぐ秘訣とは?
一段と信頼性の高いシステムを顧客が求めるようになり、勤務時間外や夜間の対応など、技術チームへの要求も増しています。本レポートでは、19,000 社以上、100 万人を超えるユーザーで構成されるPagerDutyプラットフォームから収集したデータを基にしたシステム運用の”今”を解説!→ PagerDutyの資料をみる(無料)


2014年、私はエンジニアリングマネージャーとしてPagerDutyという将来有望なスタートアップ企業に入社しました。2013年にシリーズAで融資を受けた当社は、超高成長モードに入り、あらゆる分野で積極的な採用を行いました。当時、エンジニアリングチームは30人足らずで、急成長する組織が直面する構造的な問題について学ぶことはとても魅力的でした(今もそうです)。Dutonians(PagerDutyで働く仲間)のエンジニアが数百名に達する今、これまでの変化を振り返ってみるにはちょうど良い時だと思います。
組織構造の進化は興味深いプロセスです。たくさんの失敗や行き詰まり、車輪の再発明、そして願わくは、教訓があります。エンジニアリング組織を扱う文献は山ほどありますが、ほとんどは、長所と短所を理論的に扱ったリストか、執筆時に企業が採用しているプロセスを賞賛するブログ記事のどちらかに要約されます。私はこれまでと違うアプローチで、当社のエンジニアリングチームが、構造を継続的に実験して進化させるに至った歴史的な理由を、失敗や学習も含めて、検証したいと思います。
注記:都合上、一部の出来事や詳細は簡略されていますが、多くはそれだけで記事として掲載する価値があるものです。新しいコンテンツを見逃さないよう、当ブログのブックマークをおすすめします。.
目次
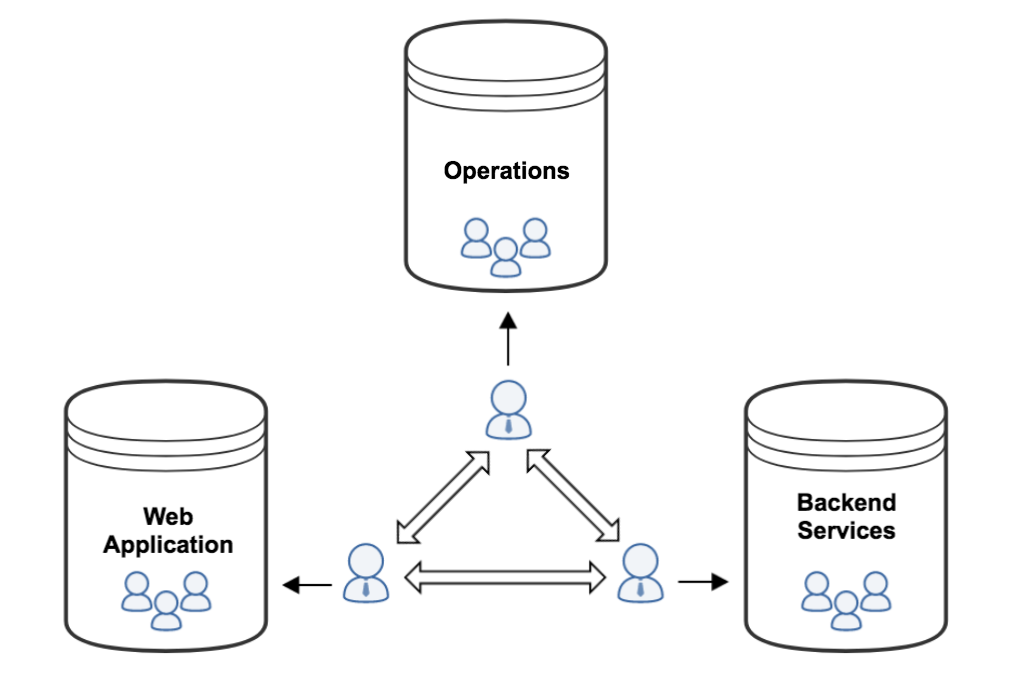
エンジニアリングチームは、非常に短期間で、ごく少数のスタッフから分散した複数のチームへ拡大したため、製品開発プロセスは未熟なままでした。スタンドアップやスプリントで表面的にはアジリティを装っていたものの、基本的にはウォーターフォールモデルでした。つまり、経営陣が取り組むべきプロジェクトを決定し、個々のエンジニアにそれらのプロジェクトを割り当て、目標納期を設定していました。当然ながら、納期に間に合うことはほとんどなく、プロジェクト追跡用のスプレッドシートはいつまでたっても修正が必要な状態で、最終的に使われなくなりました。
現場の状況も良くありませんでした。新しいプロジェクトを開始するにあたって、プロダクトマネージャーは長々とした機能設計の仕様書を作成しました。最善を尽くして起こり得るあらゆる質問を想定したのです。これは、開発中にプロダクトチームとエンジニアリングチームの交流が非常に少なかったことによるものでした。仕様書は、Webアプリケーションチームとバックエンドチームに提示されるのですが、その後、両チームは別々にユーザー向けとバックエンド向けの作業に取り掛かりました。新しいインフラの導入は、数週間前にオペレーションチームに依頼する必要がありました。
バラバラの作業すべてをまとめて一貫した機能のリリースに統合することは、悪夢でした。インフラは足りないか不完全で、厄介なバグ、機能ギャップ(どのチームも他のチームが対処していると思っている)があり、エンジニアメンバーとプロダクトメンバー共にオーナーシップやエンパワーメントに欠き、スケジュールの遅れ、組織的なサイロなどがありました。納期に間に合わせようとしてリスクを取ることが少なくなり、実装も保守的になり、製品仕様の調整にも嫌々対処していました。
この部門構造と開発プロセスが組み合わさったことで、サイロ化はエンジニアリング部門におけるあらゆる議論を押しのけ、その年の最大のテーマになりました。私たちはサイロ化していたのです。
一連の職務は厳密に決められていたため、どのチームにも機能横断的なコラボレーションを行う余裕がなかったのです。私たちは「ワーキンググループ」というコンセプトで簡単な実験を行いました。つまり、既存のチームから選ばれた人で構成される、少人数かつ多様性のある一時的なチームです。その目的は、特定の範囲における期限付きの分野横断的なプロジェクトに取り組むことでしたが、結局この実験は、当初のチームを不安定に陥れてさらなる混乱を招いたため、中断されました。
それでも、協力することが必要でしたし、一貫性と予測可能性を向上させることは何より重要でした。みんなサイロ化にうんざりしていたので、取り除かなければならなかったのです。そこで、私たちは自分たちに仕事が合うようにしました。
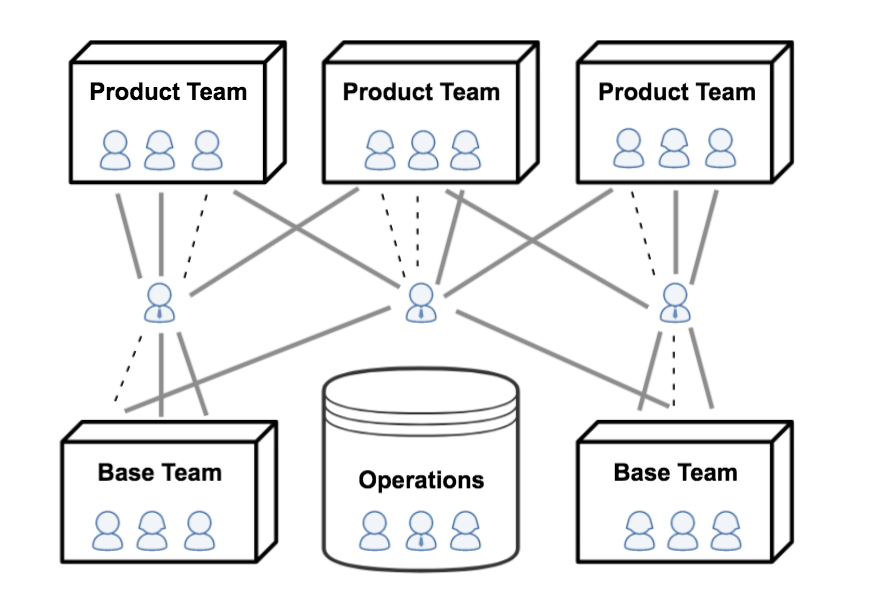
2015年の始めには、状況への不満とアジャイル方式への関心の高まりが臨界点に達し、部門再編をもたらしました。特定の製品の方向性に沿って、いくつかの新しいチームが作られました。スクラムプロセスに従って、プロダクトオーナー、スクラムマスター、UXデザイナーだけでなく、ウェブアプリケーションチームとバックエンドチームの両チームのエンジニアから構成されました。
前年の製品開発の進捗が遅かったことを考慮して、新しいチームではプロダクトデリバリーが最優先されました。彼らの時間をすべて新機能の開発に充てられるように、メンテナンス作業はバックエンドサービスチームに任されました。このチームは、かんばん方式を導入しており、「ベースチーム」と呼ばれました。全製品のオンコールを担当するほか、提供中のあらゆるサービスのオーナーシップを持つようになりました。さらに、ベースチームのメンバーをプロダクトチームに送りました。プロダクトチームの作業がスピードアップするのに伴い、エンジニアが次々に入れ替わりました。
これは明らかに大きな変化でした。チームの入れ替えによって個々のエンジニアが受ける影響を最小限にとどめるため(そしてリモートレポートへの対応を先送りにするため)、レポートラインには手をつけませんでした。そのためデュアルレポーティング構造(つまり、マトリクス組織)になり、当然、それによって日々の業務はひどく複雑になりました。エンジニアの多くは、直属の上司の管轄下にはないチームに所属することになり、マネージャーは「ピープルマネージャー」(他チームのメンバーも含め、人事を担当)と「ファンクショナルマネージャー」(別チームに上司がいるエンジニアも含め、チーム運営を担当する)の役割を果たすようになりました。
幸いなことに、古いサイロはほとんどなくなり、二度と表出することはありませんでした。ウェブアプリケーションエンジニアとバックエンドサービスエンジニアが近い距離で仕事をすることで、お互いの違いを乗り越えて理解し、共通の目標に向かって進むことができました。今でもほとんどのチームが地理的には分散していますが、二つのオフィスを一緒にしたことが功を奏しました。
総合的に判断すれば、一年前に比べだいぶ良い状態でした。しかし、まだ先は長かったのです。
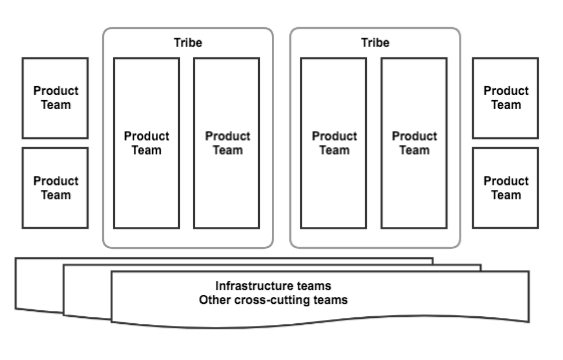
新しい組織体制を受け入れてから一年後、かなり多くの学びが蓄積されました。アジャイルは良かった(しかし十分ではない)、DevOpsも良かった(しかしこれも十分ではない)、マトリックス管理はあまり良くなかった(もう十分)ということです。
2016年の始めに再び改革を行いました。今度は「垂直的な」スクラムチームが、製品の一部を担当しました。「水平的な」チームは、製品やインフラに関する問題を分野横断的に担当し、ベストプラクティスの設定や、その他のチームが迅速に行動できるための任務を与えられました。プロダクトデリバリーチームは、ロードマップ、要件定義、実装、展開、さらに提供中の製品コードとインフラのメンテナンスも(!)担当しました。私たちは「コードを書いた者が、責任を持つ」(“you code it, you own it”)という真のDevOpsアプローチを採用しました。
GSDのテーマは、もう少し掘り下げる価値があります。私たちは実践を通して、チームの自主性、つまり発明よりもイノベーション、ビジネスは解決策の実装よりも解決すべき問題の特定、という考えにますます慣れていったのです。自分たちはお客様にとって何がベストなのかを知っている、という考え方を捨てることは簡単ではありません。MVP(MinimumViable Product/実用最小限の製品)を提供することにしっかり集中し、即座にフィードバックを獲得して、それを開発サイクル中に組み込むことが鍵でした。これにより、迅速な繰り返し、価値の最大化、予定外の機能追加を最小化でき、試作品をお客様にお届けする期間を数か月から数週間や数日に短縮できるようになりました。
プロダクトデリバリーチームの数が増えるにつれて、興味深い現象が発生しました。いわゆる「部隊」が生まれたのです(Spotifyのチームモデルのひとつです)。つまり、共通の機能やミッションによって互いに関連するチームのグループです。このモデルの導入は、オーナーシップ、知識やロードマップの共有(個々のチームのバックログとは別)、そしてビジョンの共有といったメリットをもたらしました。部隊組織については、いまだ検証中です。今後、部隊についての学びをアップデートしていきますので、ご期待ください。
この体制で数年の間運営していますが、うまくいっています。会社が速いペースで成長を続ければ、チームや関連するオーナーシップラインは確実に進化するでしょう。また、自身を向上させるための投資を続ければ、詳細も変わるでしょう。それに、多くの間違いがあったからこそ、何が正しいのかを学んだのです。
初期に下したいくつかの決断や、中間期に組織が耐えてきた厄介なことを振り返ると、なぜ明らかに優れている最終状態にジャンプしようと思い付かなかったのか、自分の頭をたたきたくなります。もちろん現実はそう単純ではありません。決定はその時の状況、プライオリティ、人員、課題に応じてなされたのです。みなさんも、自社の課題をすでに認識しているかもしれません。その場合は、私たちの経験から何かを得てほしいと思います。
組織は成長し成熟するにつれ、成長の減速、硬直化、保守的になるなどの傾向があります。私たちは、継続的な改善を実践して業務を進化させることで、時の流れに逆らい、よりアジャイルに、実用的かつ生産的に成長することに成功しました。あなたにもできるはずです。
では、次の3年間とその後の何年もの学びに乾杯!
エンジニアの燃え尽きを防ぐ秘訣とは?
一段と信頼性の高いシステムを顧客が求めるようになり、勤務時間外や夜間の対応など、技術チームへの要求も増しています。本レポートでは、19,000 社以上、100 万人を超えるユーザーで構成されるPagerDutyプラットフォームから収集したデータを基にしたシステム運用の”今”を解説!→ PagerDutyの資料をみる(無料)

この記事が気になったら




PageDuty公式アカウントをフォロー
 関連ブログ記事
関連ブログ記事
 人気記事
人気記事 検索
検索 タグ
タグ目次












