チームが効果的にインシデントに対応するには、いつインシデントが起こったのかを認識して適切な重大度を割り当てることができるよう、共有された明確なインシデントの定義が必要です。インシデントの定義はチームによって異なりますが、どのような定義であっても、鍵となるサービスレベル指標(SLI)を特定してモニタリングすることで、いつまでサービスが正常に運用していたのか、そしていつインシデントを起票すべき程度までパフォーマンスが低下したのかを把握できます。
Datadogは、インフラストラクチャや、アプリケーションパフォーマンス指標(SLIを含む)のモニタリングとアラートを支援します。この記事では、PagerDuty とDatadogを使用することでインシデント対応プロセスを強化・加速し、平均修復時間(MTTR)を短縮するための4つのベストプラクティスについて、説明します。
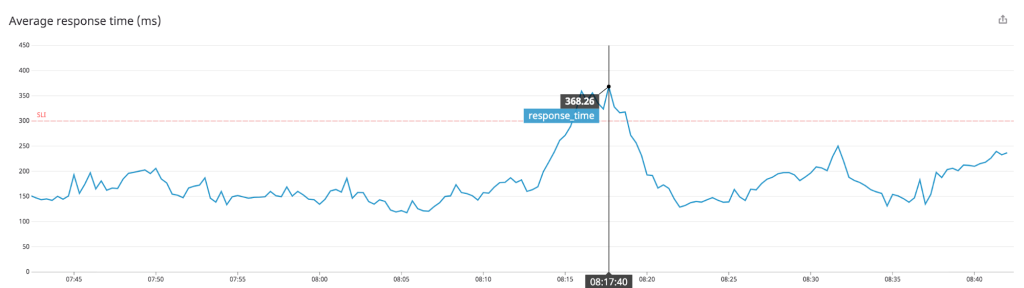
Datadogは、役立ちそうなあらゆる指標を簡単に収集できますが、すべての指標がSLIになるわけではありません。良いSLIとは、意図したサービスレベルを提供する上で、意味のある挙動を測定する指標です。例えば、レイテンシーを最小化する目的でAPIを運用する場合、APIの応答速度、エラー率、サーバーのシステム負荷をモニタリングしているとしても、応答時間をSLIとして使用すべきです。
サービスレベル目標(SLO)は、サービスやアプリケーションのパフォーマンスに対するチームの目標です。例えば、上記SLIの例(応答時間)は「300ミリ秒以内に99.99パーセントのリクエストに応答する」といったSLOの定義に使用できます。サービスレベルアグリーメント(SLA)は、組織のお客様に対するコミットメントです。各SLAは、SLO及びそのSLOを達成しなかった場合の結果、例えばお客様が支払った月額料金の一部返金などで構成されています。
組織がSLAを達成するためには、チームがSLOを満たす必要があります。進捗を追うには、正しいSLIを特定して、注意喚起する必要があります。SLIが達成できない場合、それは明確な優先事項になります。インシデントを作成し、PagerDutyとみなさんのチームのインシデント対応プロセスを頼りにして、SLOを満たしていないあらゆる挙動を修正する必要があります。
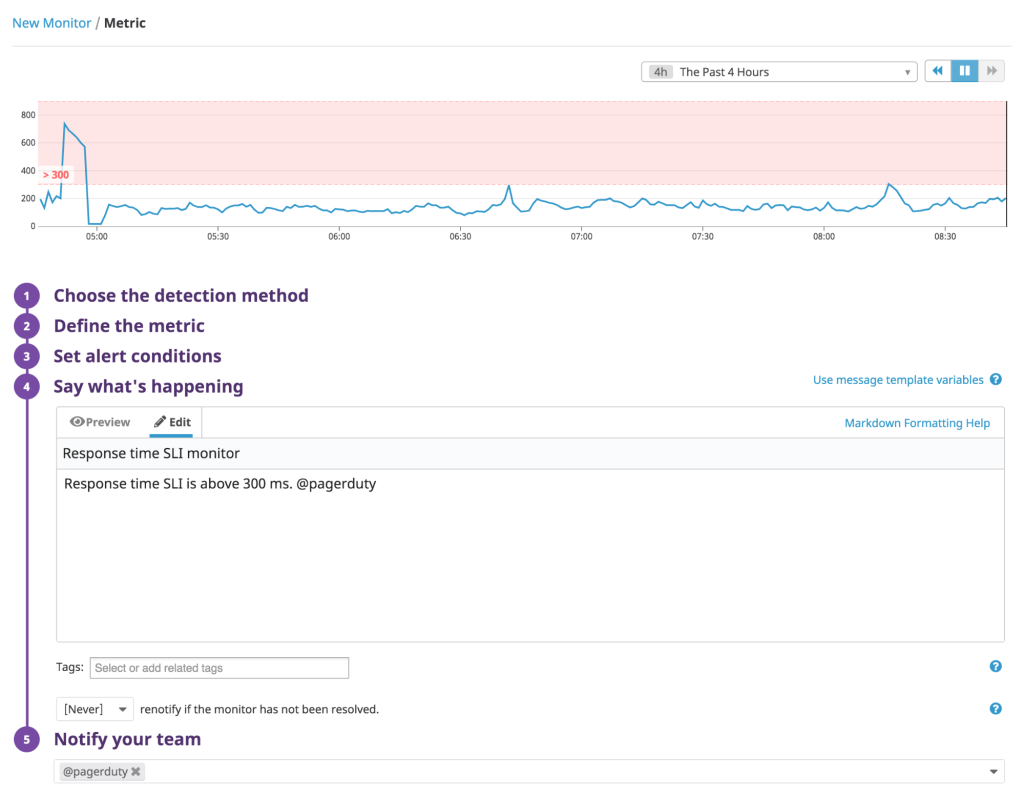
インシデントを確実に検知して、迅速な対応を開始するには、SLIが閾値を超えた際にインシデントを作成するプロセスを自動化する必要があります。PagerDuty を Datadogと統合(インテグレーション)すれば、DatadogのアラートがすぐにPagerDutyのインシデントを起票し、チームのインシデント対応プロセスを開始することができます。インシデントを自動的に作成するためには、DatadogでSLIに基づくアラートを定義し、アラートの本文で@PagerDutyをメンションします。
アラートが起動すると、Datadogのイベントストリームにイベントが表示され、インテグレーションがPagerDutyでインシデントを作成します。指標のアラート状態がそのまま解消された場合は、インテグレーションがPagerDutyのインシデントを自動的に解決します。このように、インシデント対応チームは何もしなくても、PagerDuty では今後に備えてインシデント履歴を残します。
インシデントを自動的に作成することで、対応プロセスを加速するほか、チームのSLO未達回数を履歴として確実に残すことができます。この履歴データは、インシデントが作成された回数や、いつ、どのサービスに影響を与えたのかを表示するPagerDutyインシデントトレンドレポートで見ることができます。
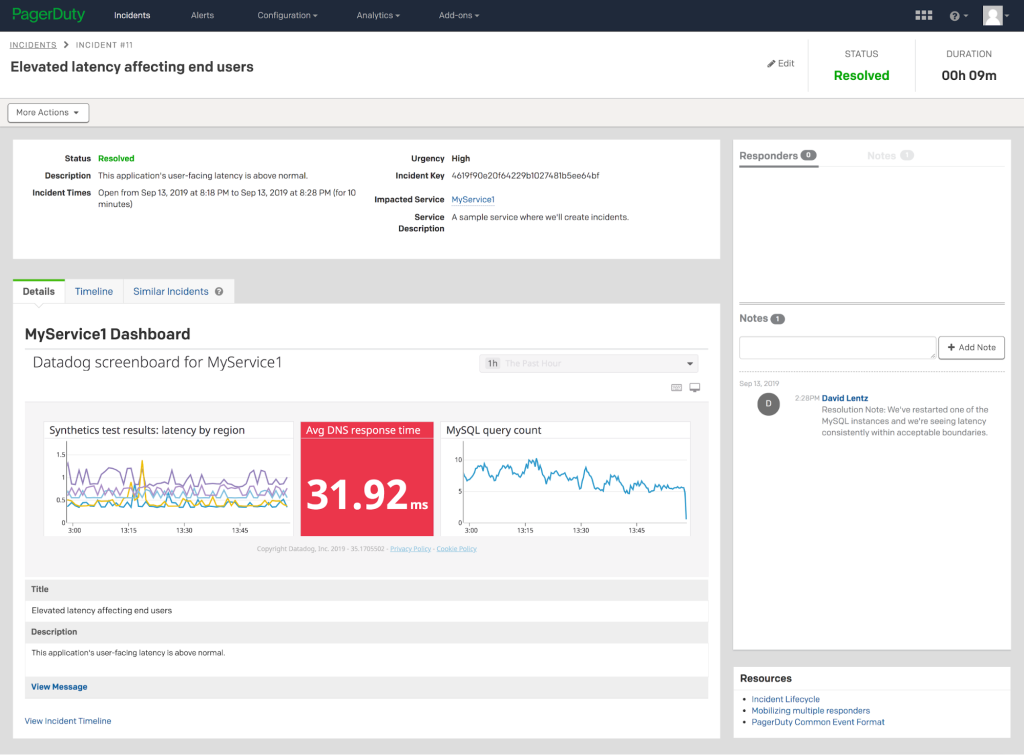
インシデントの解決を加速するには、担当者は各インシデントに関するコンテキストと最新情報(関係するサービスからの現在の監視データ、影響を受ける可能性のある依存関係など)が必要です。PagerDutyの各サービスは、各インシデントの中で関連のあるDatadogグラフやダッシュボード全体に含めるように設定することができます。これにより、担当者はSLIの基礎となるインシデントの状況や履歴を示すデータに加え、上流および下流のコンポーネントやサービスの健全性を評価するのに役立つ関連指標を見ることができます。
Datadogの合成テストを使用して、サービスやアプリケーションが依存するAPIエンドポイントの可用性やパフォーマンスを確認している場合、PagerDutyのインシデントページに表示されるDatadogのダッシュボード上にテスト結果を含めることができます。これにより担当者は、インシデント発生中に、上流のサービスの状況をすぐに確認できます。ダッシュボード上で、インシデントはサードパーティの依存関係による一時的な停止によるものだと明らかになった場合、代わりに別のサービスを使用するようアプリケーションを再設定できます。
また、上記のスクリーンショットで示されるように、アプリケーション自体の内部コンポーネント(エンドポイント、データベース、キャッシュエンジン、DNSなど)からモニタリングデータを収集して、インシデントダッシュボード上に表示できます。これらコンポーネントのパフォーマンスをモニタリングすることで、インシデントの原因を説明できる問題を見つけることができます。
PagerDutyとDatadogを統合することで、どちらのプラットフォームにもリアルタイムのインシデント情報をシームレスに追加・更新できるため、チームメンバーは完全で最新の情報を手元で確認できるようになります。
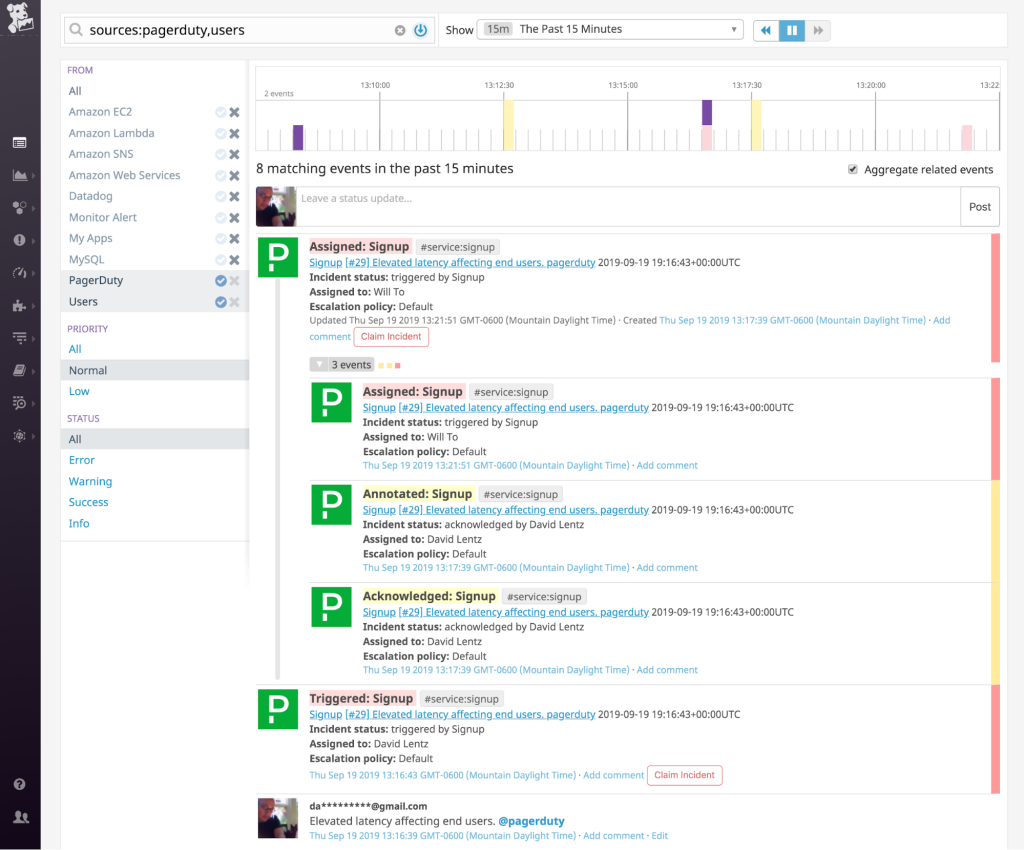
PagerDutyで収集または作成したインシデント情報は、自動的にDatadogに送信され、すべてのチームがインシデントに関する情報を確実に入手できるようにします。インシデントが”受任(Ack)”または”委譲”されたときなどは、PagerDutyのインシデントからの情報で、Datadogのイベントストリームを継続的に更新するように、インテグレーションを設定できます。これらのイベントをDatadogのグラフに重ね合わせて指標を関連付けることで、インシデントの範囲、影響、潜在的な要因を調査することもできます。
チームがPagerDutyのインシデントを更新する場合、例えば、インシデントのステータスを”解決”に変更したり、PagerDuty UIのNotesフィールドにメモを追加したりするときは、それらの変更を自動的にDatadogイベントストリームに表示することができます。
また、Datadogのモニタリング情報をPagerDutyのインシデントに自動的に追加するようインテグレーションを設定できます。Datadogのアラートが起動した場合、自動的にPagerDutyにインシデントが作成されますが、Datadogのイベントストリームに @PagerDuty とメンションしたイベントをポストすることで、いつでも手動でインシデントを作成することもできます。
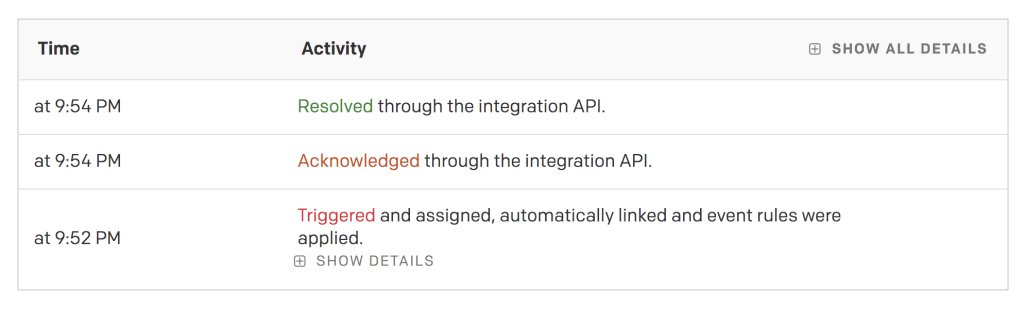
イベントストリームから直接インシデントのステータスを”受任(Ack)”または”解決”に変更するには、@PagerDuty-acknowledge または @PagerDuty-resolve とメンションしたコメントをイベントに追加します。その結果、以下のスクリーンショットで示されるように、PagerDuty UI内で変更を行ったかのようにインシデントが更新され、”受任(Ack)”と”解決”にステータスが変更されます。
PagerDuty とDatadogを統合して最大限に活用
迅速で効果的なインシデント対応によって、お客様とビジネスへの悪影響を最小限に抑えることができます。PagerDuty と Datadogを統合することで、インシデントを自動的に起動して、関連データを単一のビューで可視化し、平均修復時間(MTTR)を短縮することができます。まだDatadogをご利用いただいていない場合は、14日間の無料トライアルをお試しください。
 ソリューション解説動画
ソリューション解説動画
現代のシステム運用を取り巻く課題 / 現場エンジニアを救う処方箋とは?
システムが複雑化し、その変化も加速する中、システム運用を担う現場エンジニアの負荷は日々高まっています。
「インシデント対応」を例に、具体的に現場でどのような課題があるのかをご紹介。
そして、それらの課題をPageDutyがどのように解決できるのか、デモを交えて解説します。→ PagerDutyの資料をみる(無料)