NTTデータ様 事例
大規模組織における
「インシデント対応設計方法」
NTTデータ様では、決済をはじめ様々なシステムのパブリッククラウド化に取り組む中で、SRE/CCoEとしてPagerDutyを標準的に活用可能とする設計を実現しています。
「大規模組織においてPagerDutyを展開するための設計・展開方法」を動画で解説!→ PagerDutyの資料をみる(無料)


サイト信頼性エンジニアリング(SRE)チームを構築することは、簡単ではありません。SREの意味についてはたくさんの記事と説明がありますが、分かりにくいものです。個々のSREの役割を理解するだけではなく、SREのチームを構築して、規模を拡大することは実に大変です。SREチームを次のレベルに引き上げられるように、適切な情報を見つけることが重要です。
最近、Gremlin社のプリンシパルSREを務めるTammy Bryant氏と、ポッドキャストの“Page it to the Limit”で、SREの重要性や正しい文化を持つチームを構築する方法について話し合いました。この記事では、 Bryant氏と共有したいくつかのベストプラクティスを踏まえて、SREの役割を定義するだけではなく、SREチームを構築して規模を拡大する実践的な方法について掘り下げていきたいと思います。
目次
この記事の目的は、サイト信頼性エンジニア、つまりSREを定義し直すことではありません。SREという用語は、いろいろな所で定義されています(最も包括的な情報については、GoogleのSRE ブックをご確認ください)。SREについての説明で私が気に入っているBryant氏の言葉があります。「SREは組織全体のあらゆるチームと連携し、常に信頼性の目標を達成できるようにします。彼らはエンジニア、教師、メンター、『オートメーター』です。彼らはデータドリブンで、お客様を第一に考えています」。
「SREの最も重要な使命のひとつは、人々が毎日利用し、頼りにしている本当に重要なサービスを支えるソフトウェアやシステムを保護、提供、進歩させることです。そのため、耐久性、可用性、レイテンシー、パフォーマンス、キャパシティに常に目を光らせている必要があります」。
– Gremlin社、プリンシパルSRE、 Tammy Bryant氏
一般に、SREは開発チームと運用チームの橋渡しをして、システムの信頼性を確保し、可用性、レイテンシー、パフォーマンス、効率、変更管理、モニタリングに責任を持つことが期待されます。
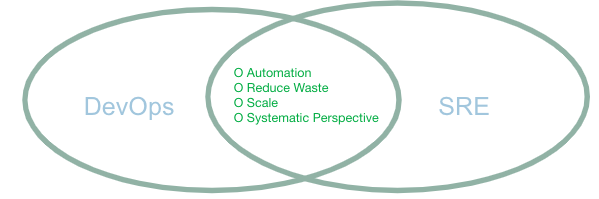
DevOpsの世界では、DevOpsとSREがよく混同されます。重複する分野もありますが、DevOpsは「何を」すべきなのかに、サイト信頼性エンジニアリングは「どのように」すべきなのかに、重点を置いています。
SREの基本については以下の記事でも詳しく解説しています。ぜひ併せてご覧ください。
> 「SRE(サイト信頼性エンジニアリング)」とは?〜DevOpsとの関係・実践ポイントを解説〜
現在のデジタル世界において、SREは重要な役割・チームです。Bryant氏は「システムやサービスが稼働していないなら、お客様はサービスを利用することさえできません」と言います。
前述したように、SREの役割と責任は、パフォーマンスと信頼性に重点を置いています。SREは単なる「コーディングをする運用担当者」ではありません。分析や測定だけではなく、自動化、デプロイメント、構成管理、モニタリングのスキルを持っています。優秀なSREはエンジニアリングのステークホルダーと連携して、信頼性と拡張性を備えた、安全な、高性能のプラットフォームを設計して提供します。連携以外にも、SREとSREチームは顧客体験を向上させる方法を模索します。また、技術トレンドを把握して、問題を解決する革新的なツールとアプローチを見つけ出します。
自動化、顧客体験の重視、信頼性といった包括的な責任について考えるなら、SREは手作業のプロセスを自動化するコードを書くことで、問題を解決するスキルが求められます。SREはたいてい、お客様(内部と外部のどちらも)が依存している重要なサービスを稼働させる責任があります。SREにとって、運用の最適化が製品に及ぼす影響や重要性、組織全体に及ぼすプラスの波及効果を理解することは大切です。またSREには、他者への共感や敏感な反応、意見や提案を受け止め、これらを迅速に技術的な解決を図るチャンスへと変える力量が求められます。
SREチームを構築するなら、チームの目標を示すガイドラインを設定することが大切です。PagerDutyでは、SREチームの意思決定プロセスを支援するために、ガイドラインが用意されています。PagerDutyのサイト信頼性エンジニアリングマネージャー、Dave Bresciは、ガイドラインで以下のように述べています。
目標を明文化し掲げて、組織全体にはっきりと示すことで、透明性、明瞭性、情報の共有化を図り、企業文化を高めます。具体的なチーム目標の例として、PagerDuty SREデリバリーチームでは、「サービスオーナーにツール、パターン、パートナーシップを提供して権限を与え、信頼性の高い、操作性に優れた、効率の良いサービスを、迅速に大規模で構築できるようにすること」を目標としています。PagerDutyでは、このような全体的なSRE目標に加えて、各SREチームが個別の目標を掲げています。
進捗状況や目標といった情報を共有する方法を考えることは、SREの構築とスケーリングを実践する際の鍵となります。私たちは、これらの目標をProduct All Hands(製品に関する全社会議)でも確認しています。目標がどのようなものであれ、明確に定義して組織と共有することで、チームのビジョンや使命を広く伝えます。PagerDutyでは、全員が参加できる社内Wikiを使って目標を共有します。また、Product All Handsでもこれらの目標を確認しています。
SREチームを運用する方法は組織によって異なります。SREの役割は、チーム内に完全に組み込むことも、チーム間で共有することも、独立したチーム内で共有することもできます。組織の変革プロセスにおける自分の位置や、SREチーム内で達成しようとしている全体的な目標を理解することは、チームの構造を決定するうえで役立ちます。
どのようなチームでも、その規模を拡大する際には、採用とオンボーディングに長い時間がかかると理解することが最初のステップです。新人が、新しいシステム、新しい働き方、新しい組織やチームの文化的なダイナミズムを学ぶには、3ヵ月から12ヵ月かかることもあります。
これは新しいチームを作ったり、そのチームの規模を拡大したりする場合も同じで、変革は一晩で起こるものではないことを常に頭に入れておいてください。そのためには、常に水平線に目を向け、次は何が来るのかを考えておくことです。チームの目標を、2、3年後になりたいと思う姿に設定しましょう。SREチームは孤立したチームではありません。将来に備えた構築だけではなく、既存環境をサポートすることもSREグループの責任だということを忘れないようにしましょう。いつ現在のシステムが壊れるのか、いつ突然パンデミックが発生して環境を大幅に拡張しなければならないのかは、分からないのです。
SREチームの拡張と修正が、現在の最適化プロジェクトを保留にする可能性があることを理解して、それをチームに伝えておくことは、チームがビジネスとお客様のニーズに集中し続けるために重要です。結局のところ、チームはすべてのレガシーシステムを扱うことにフラストレーションを感じるでしょう。レガシーシステムを壊して、作り直したいと思うものです。このため、移行と前進には時間がかかることや、進捗は日々の問題への取り組みに必ずしも表れないことを、チームに再認識させることが大切です。その対策として、小さな進歩の積み重ねを定期的にチームに思い出してもらうようにします。「半年前のことを覚えていますか?」といった質問をするのです。「新しいツールの採用率を時系列で見てみましょう」とか、「1年前は5つだったコンテナ化サービスが、今では100を超えていますね」のように、データを用いて進捗率を裏付けることも大切です。
繰り返しますが、チームを構築して規模を拡大することは簡単ではありません。この記事が、みなさんの組織がSREの旅へ出発する際に、何かを考えるきっかけになることを願っています。皆さんの体験談やヒント、感想もぜひお聞かせください。
community.pagerduty.com でこの件について私達と会話を続けましょう。SREチームの構築とスケーリングについてもっと知りたい方は、PagerDuty Summit でのTammy Bryant氏のトークや、ポッドキャストPage it to the LimitのSREに関するエピソードをご確認ください。
NTTデータ様では、決済をはじめ様々なシステムのパブリッククラウド化に取り組む中で、SRE/CCoEとしてPagerDutyを標準的に活用可能とする設計を実現しています。
「大規模組織においてPagerDutyを展開するための設計・展開方法」を動画で解説!→ PagerDutyの資料をみる(無料)

この記事が気になったら




PageDuty公式アカウントをフォロー
 関連ブログ記事
関連ブログ記事
 人気記事
人気記事 検索
検索 タグ
タグ目次












